|
|||||||||||||
|
|
|||||||||||||
       |
Feature Articles: Intelligent Spoken Language Interface Technology for Various Services Vol. 11, No. 7, pp. 28–33, July 2013. https://doi.org/10.53829/ntr201307fa5 Speech Synthesis Technology to Produce Diverse and Expressive SpeechAbstractWe have been developing a new text-to-speech synthesis system based on user-design speech synthesis technology that can be extensively applied to various fields. The technology yields speech with rich expression and various characteristics and thus replaces existing synthesized speech systems that have a limited range of voices or speaking styles. This article introduces this new system that represents the future of speech synthesis technology.
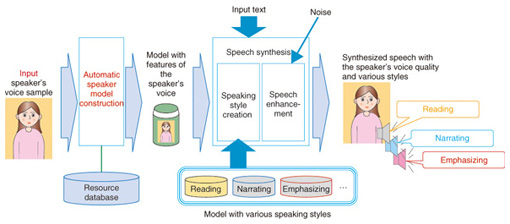
1. IntroductionThe use of mobile phone telecommunication services is continuing to increase, and this is driving demand for various speech synthesis services, for example, speech guidance and speech dialogue services. For such services, speech synthesis must offer not only high quality but also variety. For example, synthesized speech that remains audible even in noisy environments and that has a characteristic voice quality and speaking style is required. The Cralinet (CReate A LIkeNEss to a Target speaker) system originally developed by the NTT Media Intelligence Laboratories as a telephone speech guidance service can generate high quality speech [1]. Cralinet has been broadly used in a safety confirmation system and in an automatic speech guidance system for business contact centers. The main feature of Cralinet is the production of synthesized speech that is as natural as that of humans. This was achieved by using a lot of speech waveforms uttered by a narrator and properly connecting them. Unfortunately, only one voice, that of a female speaker, is output, and the speaking style is limited to reading. Hereafter, the main aim of our research and development activities will be to introduce various new speech services that satisfy a far wider range of demands. The immediate goals are to generate any kind of voice or style while retaining the usability of speech even in noisy environments. In this article, we introduce the user design speech synthesis technology, which can generate expressive synthesized speech. 2. Outline of user-design speech synthesis technologyThe framework of our technology is shown in Fig. 1. First, when the target speaker’s voice is input, a source model is selected according to the voice quality of the speaker. The source model is then trained using the acoustic features of the voice. Next, the texts given as the speech synthesis target are analyzed to determine the most appropriate speaking style, e.g., a reading, storytelling, or sales pitch style. The resulting synthesized speech thus has the voice quality of the target speaker and also the appropriate speaking style. If the end-use environment is discovered to be noisy, the speech is enhanced to permit clear discernment.
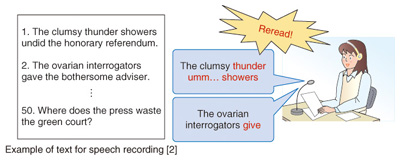
The user-design speech synthesis technology comprises three novel techniques: automatic model training, speaking style assignment, and speech clarity enhancement. Some conventional text-to-speech technologies that provide similar functions have been developed, but they have several problems. For instance, the time required to train the speaker model is excessive, speaking styles are limited, and speech clarity enhancement is effective only for a specific kind of noise. We apply our three new techniques to produce synthetic speech with rich expression and various characteristics and to realize speech synthesis with a voice similar to a user-specified speaker’s voice based on very little speech data from the target speaker. Moreover, we can generate prosody, which refers to the rhythm, stress, and intonation of speech, in order to produce speech with various speaking styles, and we can enhance speech by using noise characteristics to set speech features and thus maintain high voice quality. 3. Synthesis of various speakersRecent advances in speech synthesis technology mean that it is now possible to achieve reading out of various texts in a specified speaker’s synthesized speech, but only if about one hour of speech data is uttered by that speaker. Moreover, as shown in Fig. 2, the desired speaker must utter the set text precisely word-for-word. Reading errors are common, so the same text must be reread until the samples are error-free. This is not a problem for professional narrators, but it is impractical for the general public (family members or friends). Clearly, the amount of recorded speech data required must be reduced. Our solution is called arbitrary speakers’ speech synthesis. This solution can synthesize speech that sounds like any particular speaker from just 5 sec of the speaker’s speech data.
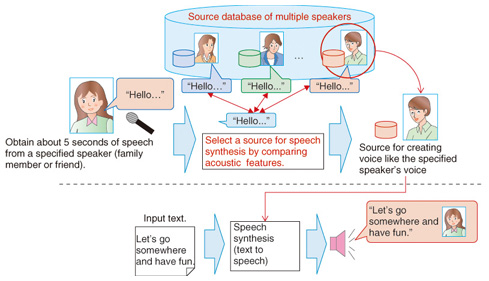
An overview of the technique is shown in Fig. 3. Samples of speech from multiple speakers are obtained in advance. These become the sound sources for speech synthesis that form the source database. By obtaining just a very small amount of a specified speaker’s speech data, i.e., a speaker not in the database, and comparing the acoustic features of that data with the previously obtained samples, a sound source can be selected from the source database to create a voice very similar to the specified speaker’s voice. This technique therefore makes it possible to synthesize speech that sounds like any particular speaker based on only 5 sec of the speaker’s speech data. Experiments confirmed that 70% of the speakers selected from the database using this technique had a similar voice to the target speaker’s voice.
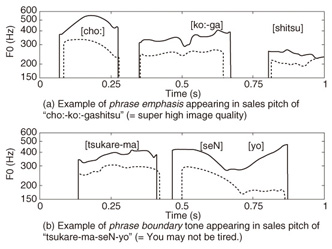
4. Expressive speaking styleThe style of speech depends on where the speech is uttered and what the intended purpose is, so adding a natural speaking style for various domains yields expressive synthesized speech. This kind of synthesis research is known as expressive speech synthesis and is being researched worldwide. Style can be expressed by three factors: i) intonation, ii) speed, and iii) loudness of speech. The style is determined by combining these three factors. Of these factors, intonation is known to be the most perceptible factor. We recorded both conventional reading style speech and expressive style speech, and compared their intonations. We observed that 1) expressive speech had higher intonation than reading speech in many phrases when a phrase-by-phrase comparison of fundamental frequency (F0) was done, and 2) there are various F0 movements at phrase-end positions, for example, rise, fall, rise-fall, and rise-fall-rise. The first observation is described as phrase emphasis, and an example of higher F0 is shown in Fig. 4(a). The second is called the phrase boundary tone. As shown in Fig. 4(b), although the phrase boundary tone in reading style speech falls towards the phrase end, e.g., “Tsukare-masen-yo
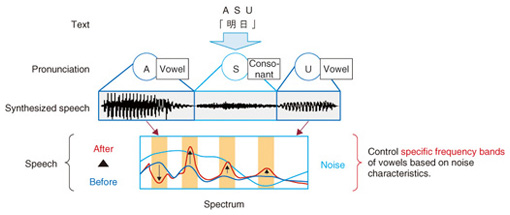
These two phenomena of phrase emphasis and phrase boundary tone are found to be useful as F0 generation control factors when synthesizing speech with the hidden Markov model (HMM), which is commonly used in many studies [3]. To achieve expressive text-to-speech synthesis (which takes text as input and generates synthesized speech as output), we investigated a method for predicting whether or not the phrase boundary tone rises at each phrase end [4]. For this prediction, it is not sufficient to know the identities of the phrase-end particles. Phrase boundary tones change with the context surrounding the phrase boundary and the situation in which the speech is uttered e.g., “A-ka 5. Enhanced synthesized speechTo apply synthesized speech to a wide variety of speech services, the synthesized speech must not only be expressive but also intelligible. In noisy environments, speech can be hard to follow unless some form of noise cancellation is used. Hence, we have been developing a technique to enhance synthesized speech. It yields synthesized speech that remains discernible while retaining as much of the distinctive characteristics of a speaker’s voice and speaking style as possible. As the first step, we analyzed the attributes of easily discerned speech in noisy environments. It is well known that some speakers have voices that carry exceptionally well; they cut through noise and are easily heard. We investigated the attributes of such carrying voices using many speakers and several types of noise. The experiments revealed that the carrying voices had a higher power spectrum in specific frequency bands occupied only by vowel sounds (which are produced by vibrating the vocal cords) than the noise [5]. As the next step, we developed a technique that uses the results of analysis to reproduce the carrying voice without changing the unique characteristics of the speaker’s voice. This is done by accentuating the power spectra of the specific frequency bands so that they dominate the identical frequency bands of the noise. The direct enhancement of power causes unexpected and unwanted changes in voice quality. Therefore, our enhancement algorithm first identifies the vowel parts of the synthesized speech from pronunciation information generated in the speech synthesis process. Next, the power spectra of the frequency bands are increased. It is difficult to precisely determine the frequency bands from actual speech in real time because the bands vary with the pronunciation. However, with speech synthesis they can be accurately determined prior to their use by analyzing the speech source. Therefore, synthesized speech that is both intelligible and high in quality can be achieved by using both pronunciation information and the frequency characteristics at specific bands, as shown in Fig. 5. The result is conductive to an increase from 50–60% to 80% in word discernment. This result indicates that the technique significantly increases the appeal and utility of synthesized speech.
6. ConclusionThe techniques introduced in this article are able to yield expressive synthetic speech with high voice quality and various speaking styles and that offers excellent clarity even in noisy environments. With these techniques, the range of applications of speech synthesis will expand greatly from the conventional applications, which have been restricted by the limited variety of speech and use environments. When the expressive speech synthesis technique described here is refined, the usage of speech synthesis will expand to encompass speech dialogue systems that can talk with various voice qualities and speaking styles in accordance with user requests. Optimizing the techniques introduced in this article is our immediate goal. References
|
||||||||||||