|
|||
|
|
|||
       |
Front-line Researchers Vol. 11, No. 7, pp. 1–6, July 2013. https://doi.org/10.53829/ntr201307fr1  Committed to Easy-to-understand Explanations without Specialized TerminologyAbstractA translation machine that would allow anyone to communicate smoothly in real time with people in all sorts of countries and regions sounds like a fantasy, but the day that such a machine becomes a reality is not really that far away. Senior Distinguished Researcher Masaaki Nagata is a leading researcher of natural language analysis in Japan. We asked him to tell us about trends and issues in machine translation as well as his views on what being a researcher means.
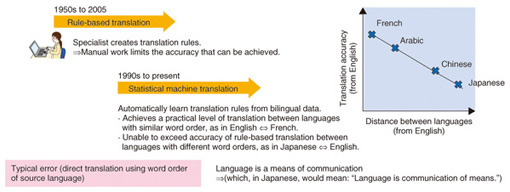
World-leading statistical machine translation technology—Dr. Nagata, please tell us about the research you are currently involved in. Right now, I’m in charge of research conducted on statistical machine translation. This is a technology for achieving machine translation by using a huge amount of bilingual data compiled from previous translations to derive a statistical model corresponding to translation rules and a bilingual dictionary. In general, the conventional machine translation process consists of analyzing a sentence in the source language, examining its structure, replacing words in that sentence with those in the target language, and reassembling the sentence in the target language. Specifically, this entails identifying parts of speech like nouns and adjectives and using the grammar of the source language to determine the syntax of the sentence, that is, the subject and predicate, the main clause and subordinate clause, and so on. Then, once the syntax has been determined, a dictionary can be used to replace words in the source language with those in the target language. This would be a Japanese-English dictionary in the case of Japanese-to-English translation to replace Japanese words with English words. Finally, the word order in the source language, for example, subject-object-verb, must be changed to fit the grammar of the target language. This method is implemented in line with grammatical and other types of rules and is therefore referred to as rule-based translation. In this scheme, a specialist creates translation rules based on his or her own knowledge and expertise. This kind of manual work, however, is extremely complicated, and it limits the accuracy that can be achieved. For this reason, “statistical machine translation” that automatically learns translation rules from a huge corpora of bilingual data has become the mainstream approach (Fig. 1).
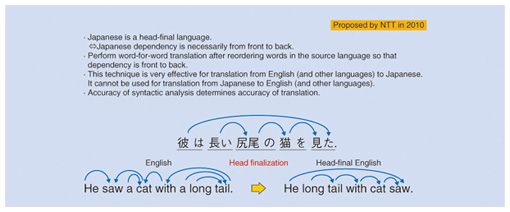
This change from manually created rules to an automatically learned statistical model fits the recent pattern of technologically imitating human functions with computers, as in speech recognition and computer vision. It is difficult for rules created on the basis of human experience to be comprehensive, which is why this shift to statistical machine translation has taken place. Another factor affecting translation accuracy is the distance between the languages in question. For example, grammar and word order in Korean are quite similar to those of Japanese, and as a result, meaning can be conveyed by simply replacing words using a bilingual dictionary. In contrast, English, which most Japanese people would probably need to have translated, can be ranked as the language furthest away from Japanese. French, meanwhile, is much closer to English, and high-accuracy machine translation between these two languages has come to be achieved relatively early. Translation is not very simple, however, between English and Japanese. Recently, though, NTT proposed a technique that uses the “head-final” property of the Japanese language to translate English to Japanese after rearranging the English word order to that of Japanese. With this approach, we have succeeded in raising the translation accuracy. —Can you explain this using a specific example? Of course. Let me give you an example of translating an English sentence into Japanese using this technique. In a phrase, which is a component of a sentence, the head is a word that determines the grammatical role of that phrase. In a prepositional phrase, for example, the preposition is the head word. To put it another way, the word in a phrase that is modified is the head. In this regard, the head-final property of Japanese means that the preceding word must modify the following word; that is, a modified word is almost always positioned toward the rear of the sentence with respect to its modifier. This property is rare among world languages. In English, however, when a verb is present, the subject modifies it from the front while the object modifies it from the back. When a noun is present, moreover, an adjective modifies it from the front, and a preposition modifies it from the back. In the above sense, English has properties different from those of Japanese. In accordance with the head-final property of the Japanese language, English words in the source document can be reordered so that modified words definitely come after their modifiers. In this way, the English word order is made to be the same as that in Japanese, and natural Japanese can then be achieved by simply performing a word-for-word translation (Fig. 2).
In summary, the preordering translation system that we have proposed obtains Japanese readings from English text according to the essentially same rules established for obtaining Japanese readings from classical Chinese text. This process consists of an intermediate step in which English words are rearranged in the way that Lou Oshiba (a popular Japanese entertainer) speaks English using Japanese grammar and a final step in which that result is revised into correct Japanese (Fig. 3).
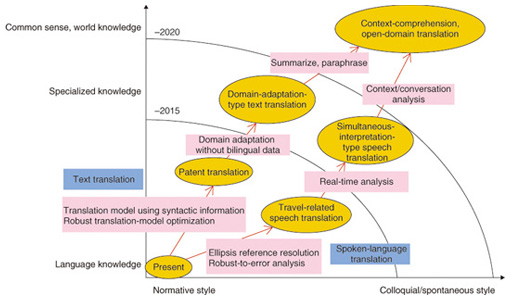
The problem here, however, is that, while we feel that translation to Japanese by this preordering technique has nearly reached a practical level, there are many unsolved problems in applying the technique to Japanese-to-English translation. At present, while we are working to improve the accuracy of English-to-Japanese automatic translation toward an actual product level, we are researching new systems for Japanese-to-English translation. One direction that future research of statistical translation and language analysis will take is establishing a technique for identifying the subject from a sentence that omits it, which is typical of the Japanese language. This is the portion in Fig. 4 indicated by “ellipsis reference resolution.” A function for translating “informal sentences” in the spoken language is difficult, but I think that translation of formulaic conversation as used, for example, in traveling, can be provided at a relatively early date. Beyond that, we envision a system that will enable smooth conversation with people who speak another language through real-time, that is, simultaneous, interpretation-type translation equipment. However, in the case of technical documents such as patent applications, I think we can reach a practical level in the near future.
Can a self-proclaimed language geek build a translation device by studying computer technology?—How did you come to be involved in language analysis? Actually, I was a “language geek.” Even today, whenever NHK begins a new language course, I cannot help but give that language a try. I wouldn’t say that speaking English is my forte, but my listening comprehension is good. I am capable of basic communication in Chinese, and during a time when I was studying Korean intensively, I was able to enjoy popular Korean TV dramas without resorting to subtitles. In my younger days, I enjoyed traveling overseas and visited more than 20 countries. French came in handy when I was lost in the old part of a Moroccan city and needed to ask directions, while German proved useful when I arrived in Prague by train late at night and had to make a hotel reservation by phone from the station. It is fun having unexpected experiences in strange countries that run counter to what one is used to in everyday life. At university, however, I majored in information science. At that time, about 30 years ago, the objective was to develop people adept at creating both hardware (electronic circuits) and software, so what I studied is probably quite different from what today’s computer science students—who have probably never seen a soldering iron—are studying. While in school, I was mainly involved in speech-related research. I worked in a laboratory that dealt not so much with language as with pattern recognition with the aim of implementing functions corresponding to human eyes and ears on the computer. Then, upon entering NTT, I was assigned to a group researching language processing, so I guess that would be the real beginning of my current research. A demonstration style born out of a desire to have people appreciate research resultsWhy is research on language processing necessary? Today, language processing is being widely used in search sites, translation sites, and elsewhere on the Internet, so the need for research in this field should be easy to understand. However, at the time that I began my research, NTT had been a private company for only two or three years. It was a time when the business of NTT was centered around the telephone, that is, voice communications, and image communications such as with fax machines. Inside the company, the section that dealt with word and language processing focused only on telegrams and directory assistance. Language processing is a forward-looking type of research, so it was hardly mainstream at that time. So, as to why I continued to research language processing, it’s probably because I enjoyed it above and beyond the fact that this research was necessary. In the second half of the 1980s, soon after entering NTT, I was lent out to Advanced Telecommunications Research Institute International (ATR). I had wanted to do some innovative research, and I spent four years researching the creation of what is today called an “automatic interpretation telephone.” In that research, we constructed a system that combined speech recognition, machine translation, and speech synthesis as the worlds’ first automatic interpretation telephone in a joint experiment with German and American universities. At that time, a demonstration of this translation system that we had constructed with enormous effort was receiving worldwide attention. I learned two things from that experience. To begin with, the research that I was actually involved in concerned the creation and input of rules by a specialist in so-called rule-based translation. I took up this research with much enthusiasm for the four years that I was at ATR. Nevertheless, we were not able to construct a very good system, and I became aware that it would be necessary to research the automatic learning of rules from language data. Second, by presenting research results in the form of a demonstration, I found that I was really able to feel how people were responding. I found this to be very interesting. For a researcher, it is not enough to simply write a paper—he or she should lose no time in trying to move people with the results achieved. My former supervisor at university would always say, “It’s not that ‘examples are necessary, it’s that ‘examples are everything.” Giving that demonstration reaffirmed those words in my mind and established my demonstration style for good. Results must be conveyed to non-specialists in an easy-to-understand manner—What is a typical day for you? Can you tell us something about your research style? I am also a group leader, so I must divide my time between correspondence, meetings, and other responsibilities, which does not give me sufficient time to spend on research. Nowadays, when listening to and discussing reports from researchers in our group, I often make decisions on our direction of research. And when reading papers and research reports in general, I like to consider what might be the next big thing in research. Furthermore, when writing a paper, I don’t do anything special to be inspired, but I always strive to write in an easy-to-understand manner using good examples. Expressing principles as straightforwardly as possible is extremely important. As for criteria in assessing whether what I write is easy to understand, I am not aware of anything in particular other than asking myself whether people outside the specialized fields of the NTT laboratories will be able to understand my paper. The NTT laboratories are involved in a variety of research themes, which means there is a wide range of specialized fields with each having an appropriate number of researchers. Specialized terms in one field are not necessarily understood in another field. If the significance of one’s research is not understood, the significance of continuing one’s research will not be recognized, and one’s research results may never reach the implementation stage. The desire to convey to the world what one is researching is common among researchers. Today, blogs and other Internet tools can be used for this purpose, but in my formative years as a researcher, this desire was satisfied by writing a textbook. By the way, I have recently been involved in preparing presentations as a team member, and I participate in thinking about how best to convey our research results in an easy-to-understand manner to other people. Additionally, I think we have a group of intellectually curious, energetic researchers here. Since I am older both in outlook and age, I would like to create an environment conducive to research for a young generation of researchers. I would like to help up-and-coming researchers to broaden their outlook and work with them to devise methods of expression that make it easy for others to understand the nature of our research. Having a passion to advance technology—Dr. Nagata, it appears that you had one other turning point in your life as a researcher. That’s right. When I was around 40 years old, I developed a problem with my hip joint. I was informed by my physician that I had no choice but to rest and take it easy until I was 65. I really felt that my life as a researcher had come to an end. However, thinking that there may be some other way to deal with my problem, I began to look through medical papers and discovered that a new type of surgery was available that could treat my condition. I then took it upon myself to find a doctor that could perform that surgery, and received the treatment. What occurred to me at that time was that medicine is also a world of research. There are various approaches, various schools of thought, and various opinions with respect to any one problem. Thanks to advances in medical technology, I was able to return to work, and I thought then that I would like to contribute to society in my own research field. I became passionate about my work in a different way than before, and I resolved to work ardently toward the realization of automatic machine translation. —Could you leave us with some advice for young researchers? Stick with what you want to do and what you think is right without being influenced by what people around you are saying. Today, short-term results are needed in order to be recognized within the company; the idyllic atmosphere of the past is gone for good. In addition, I share the feeling that assessments from the outside world are becoming increasingly severe. Information now travels at lightning speed, and if you are wondering what other researchers are up to, you can find out in the blink of an eye. The environment today is completely different from that of the pre-Internet era. Today, having a self-centered attitude is unlikely, and it can be difficult to stick to one’s beliefs. Nevertheless, I would say to researchers: “Maintain your sense of integrity in why you are pursuing certain research and where you are headed.” I myself will support you as much as possible, so let’s do our best! Masaaki NagataSenior Research Scientist, Supervisor, Group Leader (Senior Distinguished Researcher), NTT Communication Science Laboratories. He received the B.E., M.E., and Ph.D. degrees in information science from Kyoto University in 1985, 1987, and 1999, respectively. He joined NTT in 1987. He was with ATR Interpreting Telephony Research Laboratories from 1989 to 1993. His research interests include natural language processing, especially morphological analysis, named entity recognition, parsing, and machine translation. He is a member of the Institute of Electronics, Information and Communication Engineers, the Information Processing Society of Japan, the Japanese Society for Artificial Intelligence, the Association for Natural Language Processing, and the Association for Computational Linguistics. |
||