|
|||||||||||||||
|
|
|||||||||||||||
       |
Feature Articles: New Developments in Communication Science Vol. 12, No. 11, pp. 44–50, Nov. 2014. https://doi.org/10.53829/ntr201411fa8 Capturing Sound by Light: Towards Massive Channel Audio Sensing via LEDs and Video CamerasAbstractWe envision the future of sound sensing as large acoustic sensor networks present in wide spaces providing highly accurate noise cancellation and ultra-realistic environmental sound recording. To achieve this, we developed a real-time system capable of recording the audio signals of large microphone arrays by exploiting the parallel-data transmission feature offered by free-space optical communication technology based on light-emitting diodes and a high speed camera. Typical audio capturing technologies face limitations in complexity, bandwidth, and the cost of deployment when aiming for large scalability. In this article, we introduce a prototype that can be easily scaled up to 120 audio channels, which is the world’s first and largest real-time optical-wireless sound acquisition system to date. Keywords: microphone array, free-space optical communication, beamforming
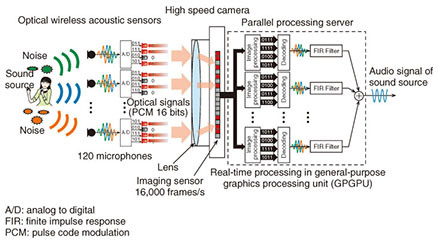
1. IntroductionImagine the TV broadcast of a live event taking place in a noisy, wide open environment. At the user end, it is often desired to have not only high quality image reproduction but also highly realistic sound that gives a clear impression of the event [1]. This can be achieved by the use of microphone arrays. According to the theory of sensor array signal processing [2], it is possible to listen to a particular sound from a desired location, and also to suppress the noise from the surroundings, by properly aligning and mixing the audio signals recorded by a microphone array. The theory also indicates that large microphone arrays produce remarkable sound enhancement. Examples have been demonstrated with arrays of 100 microphones [3]. However, to accurately record a three-dimensional sound field at a rate of up to 4 kHz and impinging from every direction on a 2-m2 wall of a room, an array of about 2500 microphones would be needed. Moreover, if the space under consideration is larger, for example a concert hall, tens of thousands of microphones might be necessary. Unfortunately, typical wired microphones and audio recording hardware have limitations in terms of complexity and cost of deployment when the objective is large scalability. Furthermore, the use of multiple wireless microphones is constrained by radio frequency (RF) bandwidth issues. To overcome these difficulties, we developed a prototype that allows the simultaneous capture of multichannel audio signals from a large number of microphones (currently up to 120). In contrast with existing RF wireless audio interfaces, the proposed system relies on free-space optical transmission of digital signals. Such technology allows the parallel transmission of multiple data channels, each with full bandwidth capacity regardless of the number of channels transmitted. 2. System descriptionOur system is composed of three main parts: 1) an optical wireless acoustic sensor (OWAS), 2) a high speed camera, and 3) a parallel processing server. The overall architecture of the system is illustrated in Fig. 1.
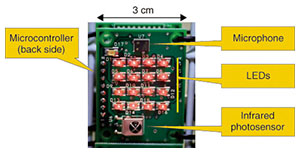
2.1 OWAS deviceAn OWAS device is shown in Fig. 2. The microphone picks up samples of the acoustic waves at a rate of 16 kHz and outputs a delta-sigma modulated digital stream. Then, a microcontroller converts that serial data into binary symbols of 16-bit pulse code modulation (PCM). The PCM symbols are used to light up an array of 16 light-emitting diodes (LEDs). An LED in the ON or OFF state means a binary 1 or 0, respectively. Because the camera can observe several OWASs simultaneously, the sound field can be sensed with a large array of OWASs such as the one shown in Fig. 3, where 200 OWAS devices have been arranged in a 5 × 40-node grid. With this array, our current experimental setup can acquire signals from 120 OWAS devices as allowed by the maximum image size of the camera. Each OWAS device is also equipped with an infrared photosensor that enables it to receive the master clock signal emitted by the pulse generator shown in Fig. 4. Therefore, the synchronization between the OWAS devices and the high speed camera is maintained through the master clock generator.
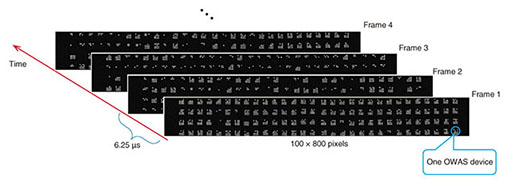
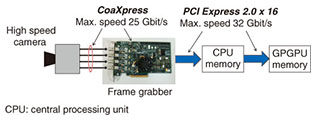
2.2 High speed cameraThe imaging sensor of the high speed camera observes the optical signals from the OWAS and records them into intensity images at the rate of 16,000 frames per second (fps). An example of the actual images captured by the camera is shown in Fig. 5. To transfer the image data from the camera to the processing server, the camera is connected to a frame grabber card installed on the PCI (Peripheral Component Interconnect) bus of the server. Thus, the flow of the image data can be seen in Fig. 6.
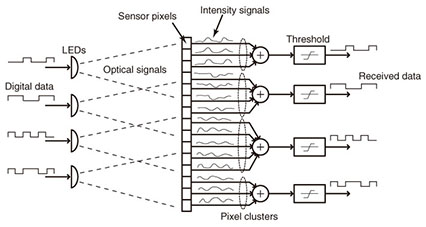
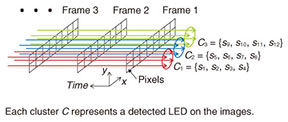
2.3 Parallel processing serverThe server is equipped with dual CPU (central processing unit) support and a standard general-purpose graphics processing unit (GPGPU), which provides enough massive parallel computing power to process 16,000 images and 120 audio channels within a real-time factor of 0.75. The process to decode the audio signals from the images starts with the detection of the LEDs on the images. Several image processing algorithms have been proposed to accomplish this [4], and it was suggested that the optical transmission channel can be modeled as a MIMO (multiple input multiple output) port as shown in Fig. 7. With this model, the pixels of the images can be organized into clusters C by analyzing the spatiotemporal correlation of their intensity signals s across a block of captured frames, as shown in Fig. 8. Each cluster of pixels represents a detected LED on the images. Once the pixels for each LED have been identified, their intensity signals are optimally thresholded to convert them back to binary symbols (see Fig. 7). Finally, the binary data is decoded to obtain the originally transmitted audio signals from all the OWAS devices.
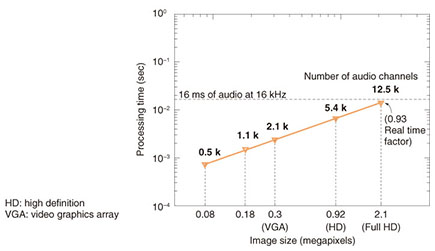
These audio signals are further processed with digital filters and mixed down to produce a single output channel (see Fig. 1). This multichannel signal processing, often known as beamforming [2], enhances the sound from the desired direction (with respect to the OWAS array), while the noise from other directions is reduced at the output audio signal. In other words, the OWAS array can be acoustically focused in any desired direction. In our preliminary experiments, we have been able to focus on the sound from targets placed as far as 10 m away from the OWAS array while suppressing the noise from the surroundings. An online demonstration video showing the experimental setup is available [6]. Furthermore, we have also achieved the optical transmission of multichannel signals at a distance of 30 m from the receiver camera [5]. Our system also has large scalability. Our numerical simulations indicated that our algorithms can receive and decode the optical signals of as many as 12,000 OWAS devices simultaneously within a single GPGPU card, therefore maintaining real-time processing, as can be seen in Fig. 9.
3. Future workThe current limitation we face in expanding our prototype involves the high speed camera. The resolution of existing commercial cameras must be considerably reduced in order to achieve high-speed frame rates (tens of thousands of fps). Nevertheless, the accelerated advances in imaging sensor and parallel computing technologies motivate us to carry out further development of our prototype. In the near future, we expect to build OWAS arrays over large spaces such as stadiums or concert halls, and we may achieve real-time position tracking of portable/wearable OWAS devices. Such progress will pave the way for novel applications and high quality services. References
|
||||||||||||||