|
|||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||
       |
Information Vol. 12, No. 11, pp. 110–115, Nov. 2014. https://doi.org/10.53829/ntr201411in1 LSP (Line Spectrum Pair): Essential Technology for High-compression Speech CodingAbstractLine Spectrum Pair (LSP) technology was accepted as an IEEE (Institute of Electrical and Electronics Engineers) Milestone in 2014. LSP, invented by Dr. Fumitada Itakura at NTT in 1975, is an efficient method for representing speech spectra, namely, the shape of the vocal tract. A speech synthesis large-scale integration chip based on LSP was fabricated in 1980. Since the 1990s, LSP has been adopted in many speech coding standards as an essential component, and it is still used worldwide in almost all cellular phones and Internet protocol phones. Keywords: LSP, speech coding, cellular phone
1. IntroductionOn May 22, 2014, Line Spectrum Pair (LSP) technology was officially recognized as an Institute of Electrical and Electronics Engineers (IEEE) Milestone. Dr. J. Roberto de Marca, President of IEEE, presented the plaque (Photo 1) to Mr. Hiroo Unoura, President and CEO of NTT (Photo 2), at a ceremony held in Tokyo. The citation reads, “Line Spectrum Pair (LSP) for high-compression speech coding, 1975. Line Spectrum Pair, invented at NTT in 1975, is an important technology for speech synthesis and coding. A speech synthesizer chip was designed based on Line Spectrum Pair in 1980. In the 1990s, this technology was adopted in almost all international speech coding standards as an essential component and has contributed to the enhancement of digital speech communication over mobile channels and the Internet worldwide.”
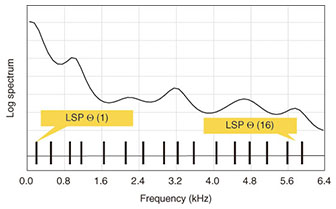
IEEE Milestones recognize technological innovation and excellence for the benefit of humanity found in unique products, services, seminal papers, and patents, and they have so far been dedicated to more than 140 technologies around the world. 2. Properties of LSPLSP is an equivalent parameter set of LP (linear prediction) coefficients a[i]. Among the various types of linear prediction, AR (auto-regressive) or all-pole systems have mainly been used in speech signal processing. In an AR system, the current sample is predicted by summation (from 1 to p, e.g., 16) of i past sample multiplied by each associated coefficient a[i]. A prediction error signal The preferable set of a[i] can be adaptively determined to minimize the average energy of prediction errors in a frame. This relation can be represented by the polynomial of z as while 1/A(z) represents the transform function of the synthesis filter. The frequency response of 1/A(z) can be an efficient approximation of the spectral envelope of a speech signal or that of a human vocal tract. This representation, normally called linear prediction coding (LPC) technology, has been widely used in speech signal processing, including for coding, synthesis, and recognition of speech signals. Pioneering investigations of LPC were started independently, but simultaneously, by Dr. F. Itakura at NTT and Dr. M. Schroeder and Dr. B. Atal at AT&T Bell Labs, in 1966 [1]. For the application to speech coding, bit rates for LP coefficients need to be compressed. In 1972, Dr. Itakura developed PARCOR*1 coefficients to send information equivalent to LP coefficients with low bit rates while keeping the synthesis filter stable. A few years later, he developed LSP [2]–[4], which achieved better quantization and interpolation performance than PARCOR. A set of pth-order LSP parameters is defined as the roots of two polynomials F1(z) and F2(z), which consists of the sum and difference of A(z) as The LSP parameters are aligned on the unit circle of the z-plane, and the angles of LSP, or LSP frequencies (LSFs), are used for quantization and interpolation. An example of 16th-order LSF values θ(1),…, θ(16) and the associated spectral envelope along the frequency axis are shown in Fig. 1. The synthesis filter is stable if each root of F1(z) and F2(z) is alternatively aligned on the frequency axis. It has been proven that LSP is less sensitive to the shape of a spectral envelope; that is, the influence of distortion due to quantization in LSP on the spectral envelope is smaller than it is with other parameter sets, including PARCOR and some variants of it. In addition, LSP has a better interpolation property than others. If we define LSP vector ΘA = {θ(1),…, θ(P)} corresponding to spectral envelope A, the envelope approximated by envelope((ΘA + ΘB)/2) with LSP ΘA and ΘB can be a better approximation of the interpolated spectral envelope (envelope(ΘA) + envelope(ΘB))/2 than that with other parameter sets. These properties can further contribute to efficient quantization when they are used in combination with various compression schemes, including prediction and interpolation of LSP itself. These properties of LSP are beneficial for the compression of speech signals.
3. Progress of LSPAfter the initial invention, various studies were carried out by Dr. N. Sugamura, Dr. S. Sagayama, Mr. T. Kobayashi, and Dr. Y. Tohkura [5] to investigate the fundamental properties and implementation of LSP. In 1980, a speech synthesis large-scale integration (LSI) chip (Fig. 2), was fabricated and used for real-time speech synthesis. Until that time, real-time synthesizers had required large equipment consisting of as many as 400 circuit boards. Note, however, that the complexity of the chip was still 0.1 MOPS (mega operations per second), less than 1/100 of the complexity of chips used for cellular phones in the 1990s.
Around 1980, low-bit-rate speech coding was achieved with a vocoder scheme that used spectral envelope information (such as LSP) and excitation signals modeled by periodic pulses or noise. These types of coding schemes were able to achieve low-rate (less than 4 kbit/s) coding, but they were not applied to public communication systems because of their insufficient quality in practical environments with background noise. Another approach for low-bit-rate coding was waveform coding with sample-by-sample compression. However, it also could not provide sufficient quality below 16 kbit/s. In the mid 1980s, hybrid vocoder and waveform coding schemes, typically CELP*2, were extensively studied; these schemes also need an efficient method for representing spectral envelopes such as LSP.
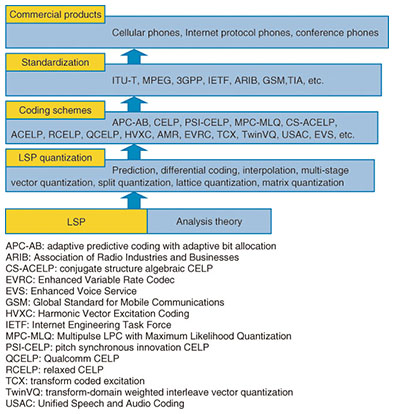
4. Promotion of LSP in worldwide standardsDuring the 1980s, however, the general consensus was that compression of speech signals would probably not be useful for fixed line telephony, and there was some doubt as to whether digital mobile communications, which requires speech compression, could easily be used in place of an analog system in the first generation. Just before 1990, however, new standardization activities for digital mobile communications were initiated because of the rapid progress being made in LSI chips, batteries, and digital modulation, as well as in speech coding technologies. These competitive standardization activities focusing on commercial products accelerated the various investigations underway on ways to enhance compression, including extending the use of LSP, as shown in Fig. 3. These investigations led to the publication of some insightful research papers, including one on LSP quantization by the current president of IEEE, Dr. Roberto de Marco [6].
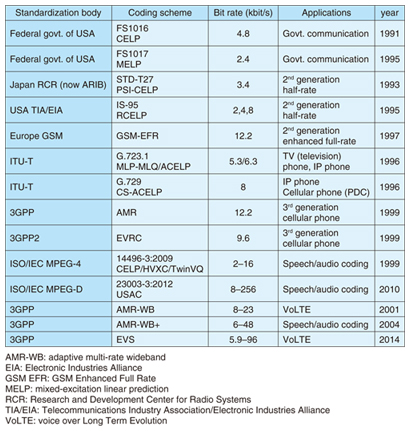
In the course of these activities, LSP was selected for many standardized schemes to enhance the overall performance of speech coding. The major standardized speech/audio coding schemes that use LSP are listed in Table 1. To the best of our knowledge, the federal government of the USA was the first to adopt LSP as a speech coding standard in 1991. The Japanese Public Digital Cellular (PDC) half-rate standard in 1993 may have been the first adoption of LSP for public communications systems; the USA and Europe soon followed suit. In 1996, two ITU-T (International Telecommunication Union-Technology Sector) recommendations (G.723.1 and G.729) were published with LSP as one of the key technologies. Both, but especially G.729, have been widely used around the world as default coding schemes in network facilities for Internet protocol (IP) phones. In 1999, speech coding standards for the third generation of cellular phones, which are still widely used around the world, were established by both 3GPP*3 and 3GPP2*4 with LSP included.
Furthermore, LSP has proven to be effective in capturing spectral envelopes not only for speech but also for general audio signals [7] and has been used in some audio coding schemes defined in ISO/IEC (International Organization for Standardization/International Electrotechnical Commission) MPEG-4 (Moving Picture Experts Group) in 1999 and MPEG-D USAC (Unified Speech and Audio Coding) in 2010.
5. Future communicationIn the VoLTE*5 service introduced in 2014 by NTT DOCOMO, 3GPP adaptive multi-rate wideband (AMR-WB) is used for speech coding, and it provides wideband speech (16-kHz sampling, the same speech bandwidth as mid-wave amplitude modulation (AM) radio broadcasting). For the next generation of VoLTE, the 3GPP Enhanced Voice Service (EVS) standard is expected to be used, which can handle a 32-kHz sampling rate signal and general audio signals. LSP or a variant of LSP is incorporated in both AMR-WB and EVS. In the near future, it may be possible to achieve all speech/audio coding functions with downloadable software. Even in such a case, we expect that LSP will still be widely used. In this way, LSP may be a good example of technology that has contributed to the world market. The NTT laboratories will continue to make efforts to enhance communication quality and the quality of services by meeting challenges in research and development.
References
|
||||||||||||||||||||||||||