|
|||||||||
|
|
|||||||||
       |
Regular Articles Vol. 13, No. 7, pp. 48–54, July 2015. https://doi.org/10.53829/ntr201507ra2 Taking the English Exam for the “Can a Robot Get into the University of Tokyo?” ProjectAbstractNTT and its research partners are participating in the “Can a robot get into the University of Tokyo?” project run by the National Institute of Informatics, which involves tackling English exams. The artificial intelligence system we developed took a mock test in 2014 and achieved a better-than-human-average score for the first time. This was a notable achievement since English exams require English knowledge and also common sense knowledge that humans take for granted but that computers do not necessarily possess. In this article, we describe how our artificial intelligence system takes on English exams. Keywords: artificial intelligence, natural language processing, Todai Robot Project
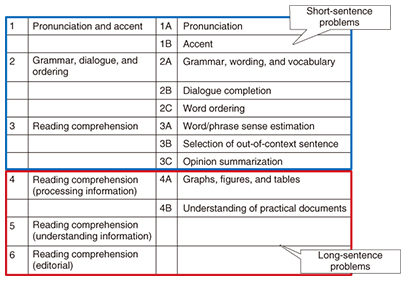
1. IntroductionThe National Institute of Informatics (NII) has been promoting the Todai Robot Project (Can a robot get into the University of Tokyo?) [1]. By developing artificial intelligence that can pass the entrance exam of the University of Tokyo (Todai), the members of the project aim to clarify the limitations of artificial intelligence and the boundaries between humans and computers. The goal of the project is to achieve high marks on the National Center Test for University Admissions (NCTUA) by 2016 and to be admitted into the University of Tokyo by 2021. NTT, together with its research partners, Okayama Prefectural University, Akita Prefectural University, Osaka Institute of Technology, and the University of Electro-Communications, joined the project to form an English team in 2014 and achieved a score of 95 out of 200 points) on a mock Center Test (Yozemi mock Center Test by the educational foundation Takamiya Gakuen) in the same year; the score we achieved with our computer program was above the national average of 93.1. This is a big jump from the previous year, because the English score in 2013 was 52, which was a chance-level score considering that all problems are multiple choice, mostly consisting of four choices. It may be a surprise to readers to learn that English is regarded as one of the most difficult subjects for computers compared with other subjects. This is because problems in English cannot be solved just by having English knowledge such as of vocabulary, grammar, and idioms. Rather, these problems require common sense knowledge. For example, there are problems in which it is necessary to estimate human emotion and the causal relationships of events. At NTT, we have been tackling problems that require common sense reasoning through the research and development of dialogue and machine translation systems. We successfully exploited our expertise in these fields to achieve a high score on the mock Center Test. To pass the entrance exam of the University of Tokyo, it is necessary to achieve high marks on both the NCTUA and second-stage exams. However, since the second-stage exams contain difficult tasks involving writing, we are currently working on the NCTUA, where there are only multiple-choice problems. The typical structure of the English exam of the NCTUA is shown in Fig. 1. There are usually six categories of problems; the first three are short-sentence problems (problems related to words and short phrases), and the latter three are long-sentence problems (problems related to long documents that may contain illustrations, graphs, and tables).
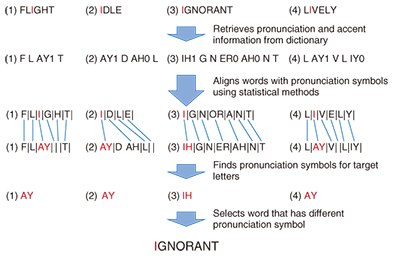
In this article, we describe how Torobo-kun (Torobo stands for Todai Robot, and kun is an honorific title in Japanese normally used for boys; the members of the project affectionately refer to the exam-solving software this way) solves questions on the English exam, putting an emphasis on our approach on short-sentence problems. Unfortunately, the current level of artificial intelligence has difficulty solving long-sentence problems, and we have not yet established a concrete method for solving them. We discuss the reason for this difficulty in the last section. Moreover, Torobo-kun is currently a type of computer software. Therefore, it does not visually see and read questions on paper, nor does it fill in answer sheets using pencils. It obtains exams in electronic form and outputs choices that it thinks are correct. 2. Pronunciation and accent (word stress) problemsProblems regarding pronunciation and accent (word stress) are not that difficult for computers because they can consult electronic dictionaries. With pronunciation, the task is to select a word that has a letter that is pronounced differently from the same letters in the other choices. An example of a pronunciation problem is shown in Fig. 2. To solve this problem, the program first consults an electronic dictionary. The dictionary here is one developed for speech recognition and synthesis research*; thus, it has pronunciation and accent information for words. Then, to obtain the pronunciation for a target letter (in this case, “I”), we calculate the most likely alignments between letters and pronunciations within the dictionary by using statistical methods. This tells us which letter corresponds to what pronunciation. Finally, since we know that the pronunciation for “I” in “ignorant” is different from the “I”s in the other choices, we can obtain the correct answer.
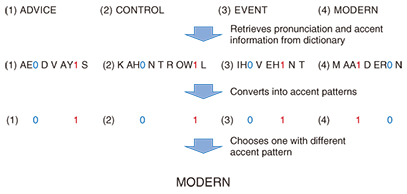
With accent, the task is to select, out of four choices, a word that has the most accented syllables in a different position compared with other choices. An example of an accent problem is shown in Fig. 3. The same dictionary is used to solve this type of problem. In the figure, alphabetic characters (letters) denote pronunciation symbols, and the numbers 0 and 1 respectively indicate whether a vowel is a non-accented or an accented one. From these 0s and 1s, we can find the accented vowels in the words and immediately determine that modern is the odd one out.
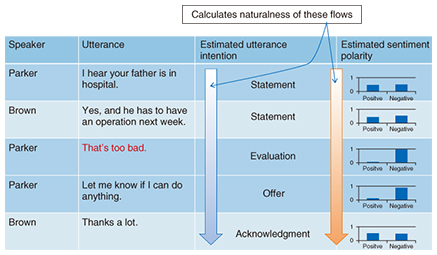
3. Grammar, wording, and vocabulary problemThe task here is to select one of the four choices that best fits in the blank in a sentence. Below is an example: In this example, the answer that best fits [A] is (3), an appointment. To solve this type of problem, we turn to a technology called statistical language models, which have been widely used in machine translation to produce fluent translations. Language models are created by statistically processing a large number of documents; they contain the probability information about how one expression follows another. Given a question, our program first creates sentences by filling in the blanks with each of the choices and calculates the fluency of each sentence by using the language models. Then, we select the choice that realizes the most fluent (probable) sentence. 4. Dialogue completion problem and opinion summarization problemIn the dialogue completion problem, it is necessary to select one utterance from four choices to fill in the blank in a given dialogue. In the example below, the utterance that best fits [B] is choice (4). To solve this type of problem, we first fill in the blank by using each of the choices and, for each case, estimate the naturalness of the conversation; the choice that achieves the highest degree of naturalness is selected as the answer. We estimate the naturalness of a conversation from two viewpoints; one is the flow of utterance intentions (also known as dialogue acts or illocutionary acts, e.g., statement, evaluation, question, etc.) and the flow of sentiment polarities, e.g., positive and negative. The flow of utterance intentions and sentiment polarities when the blank has been filled in with (4) is shown in Fig. 4. Here, the utterance intentions and sentiment polarities are those that have been automatically estimated from dialogue data using statistical methods. The conversation begins with a statement about Brown’s father being in hospital followed by another statement about the fact that he has to have an operation. This is followed by an evaluation (evaluative response), offer, and acknowledgment. The flow of these utterance intentions seems as natural as that in human conversation. As for sentiment polarities, the polarities regarding the admission to hospital and the operation match that of (4); that is, they all have negative polarities. Therefore, this flow of sentiment is also as natural as that in human conversation. On the basis of the naturalness of these two flows, Torobo-kun can select (4) as the most appropriate answer.
The task with opinion summarization problems is similar to that of the dialogue completion problem. The task in this case is to select an utterance that best summarizes a speaker’s opinion in a multi-party discussion. Since a discussion is a kind of conversation, we use the same technique as just described; that is, we select an utterance that creates the most natural flow. In this type of problem, the choices are usually of the same utterance intention. Therefore, we only leverage the flow of sentiment polarities. 5. Word ordering problemThe task in these problems is to fill in blanks in a sentence by correctly ordering given words in order to create a valid grammatical sentence. An example is shown in Fig. 5. In the example, the correct ordering for the given words is “complex for me to solve with” (the answer for this problem consists of the words that correspond to blanks [C] and [D]). For this type of problem, our program creates all possible permutations of word orderings (in the example, 720 permutations are created) and chooses the most appropriate one. To calculate the appropriateness, we turn to the statistical language models we used for the grammar, wording, and vocabulary problems.
6. Word/phrase sense estimation problemThe task in this case is to estimate the meaning of an unknown word/phrase (the unknown word/phrase may not be unknown to the computer program because it has access to dictionaries; here, unknown means unknown or unfamiliar to examinees) and to select a choice whose meaning is the most similar to the given word or phrase. Below is an example In this problem, take a rain check is the unknown phrase, and we need to select the choice that has the meaning closest to the phrase. In this example, because take a rain check means to request a postponement of an offer, the correct answer is (1). For this type of problem, we utilize a technique called word2vec [2] and an idiom dictionary. Word2vec enables us to calculate the similarity between words on the basis of their usages in large text data. The idea used here is called distributional similarity; that is, the more similar the contexts of words, the closer their meanings are. Using word2vec, we calculate the similarities between an unknown word/phrase and the choices and select the one that has the highest similarity score. Note that when the unknown word/phrase is listed in the idiom dictionary, that word/phrase is replaced by its gloss (definition statement) before calculating the similarity. This heightens the accuracy in calculating similarities. 7. Long-sentence problems and future directionsWith long-sentence problems, we apply the method used for textual entailment. In textual entailment, two documents are given, and the task is to recognize whether the content of one document is contained in the other. In long-sentence problems, there are many questions that ask whether the content of a choice is contained in a given document. Therefore, the technology for textual entailment can be directly applied. However, this approach achieved very poor results in the mock Center Test. In particular, it was difficult to absorb the differences in expressions with the same meaning and to find reasonable referents for referring expressions. It is therefore necessary to further improve the accuracy of textual entailment. In addition, it is necessary to read the minds of characters in stories, understand illustrations, graphs, and tables, and grasp the logical and rhetorical structures of documents. As sentences get longer and longer, the need to read between the lines becomes more important. Between the lines, there is common sense, and to solve long-sentence problems, it is necessary to tackle the problem of common sense head on. In the future, we will focus on solving long-sentence problems and creating programs that can achieve high marks on both the NTCUA and the second-stage exams of the University of Tokyo. AcknowledgmentWe thank the educational foundation Takamiya Gakuen for providing us with the mock Center Test data. References
|
||||||||