|
|||||||||||||||||
|
|
|||||||||||||||||
       |
Regular Articles Vol. 15, No. 4, pp. 50–56, Apr. 2017. https://doi.org/10.53829/ntr201704ra1 Low Latency Dynamic Bandwidth Allocation Method with High Bandwidth Efficiency for TDM-PONAbstractThis article describes a low latency dynamic bandwidth allocation (DBA) method with high bandwidth efficiency that is intended for use in campus area networks and mobile fronthaul based on TDM-PON (time division multiplexing passive optical network). These network systems require low latency of under 100 μs and high bandwidth efficiency. Our method involves only three steps for allocation and employs an adaptive DBA cycle depending on the traffic load. The DBA cycle length, which is proportional to the latency, can be minimized because the simple allocation steps are appropriate for hardware implementation. Our DBA method automatically optimizes the cycle length to reduce the latency and improve bandwidth efficiency. We implemented it on a 10-gigabit Ethernet passive optical network (10G-EPON) media access control system-on-a-chip and evaluated the allocation results and the latency on the 10G-EPON system. Our DBA achieved a minimum latency of 60 μs with priority control and high bandwidth efficiency, depending on traffic. Keywords: TDM-PON, DBA, low latency
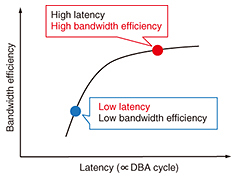
1. IntroductionTime division multiplexing passive optical network (TDM-PON) systems, such as gigabit passive optical networks (GPON) [1] and Ethernet passive optical networks (EPON) [2], have been widely deployed for fiber-to-the-home (FTTH) services because of their cost advantage over point-to-point systems. Point-to-point systems such as large campus area networks (campus-LANs) and mobile fronthaul (MFH) for the fifth-generation mobile communications network (5G) are still potential markets for TDM-PON [3, 4]. However, there are two problems with employing TDM-PON for MHF and campus-LANs. The first is the large upstream latency. In TDM-PON, dynamic bandwidth allocation (DBA) must be implemented in an optical line terminal (OLT) to avoid upstream data collisions. DBA increases the latency. The second problem is bandwidth efficiency. In general, the bandwidth efficiency decreases in proportion to the reduction in latency, as shown in Fig. 1.
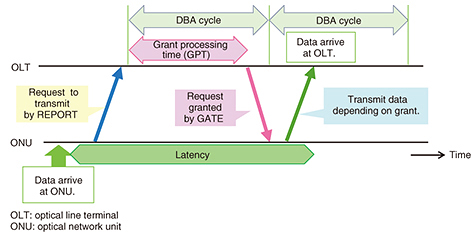
Reducing the grant processing time (GPT), which is the time taken to process the DBA in the OLT, is important to reduce the latency. The handshaking between the OLT and optical network units (ONUs) derived using the status reporting (SR) method is shown in Fig. 2. When the OLT receives all of the ONU’s REPORTs (a type of control message), it begins to calculate the transmission time and start timing for upstream data using a grant processor. The transmission time is a time slot of a DBA cycle, which is proportional to the latency. After the calculation, the OLT informs ONUs of these results by using GATEs (another type of control message) to grant each ONU’s data transmission. The length of the GPT depends on the DBA method, and a complex method increases it. The latency due to DBA for FTTH services is now on the order of milliseconds [5] because of its advanced software processing designed to achieve strict fairness.
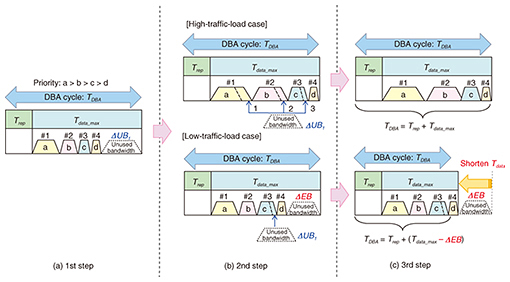
To solve the two problems specific to TDM-PON, we devised a low latency DBA method with greater bandwidth efficiency. In addition, our DBA is equipped with a priority-control function. This is because in campus-LANs, the layer-two switch has to support priority control among its ports. Thus, priority control among ONUs is an important requirement for TDM-PON-based campus-LANs. 2. Low latency DBA method to improve bandwidth efficiencyWe propose a new DBA algorithm consisting of three simple steps that is appropriate for hardware (HW) implementation. HW implementation makes it possible to reduce the GPT and the latency. In addition, we adopt an adaptive DBA cycle to improve bandwidth efficiency. The adaptive cycle length can optimize both latency and bandwidth efficiency depending on the traffic load from ONUs. Our DBA algorithm is shown in Fig. 3. It consists of three simple steps. First, the grant processor allocates a shorter time that is equivalent to the requested bandwidth (RBn, where n represents the identification number of ONU) or a guaranteed bandwidth (GBn) for each ONU. Next, it allocates the unallocated bandwidth (ΔUB1) for ONUs, requesting more bandwidth in descending order of priority. After the second allocation, in the high-traffic-load case, high bandwidth efficiency is achieved and the latency is determined as the maximum latency that has been set as an initial configuration. Last, when excess bandwidth (ΔEB) is generated, that is, in the low-traffic-load case, our DBA reduces the length of the DBA cycle to achieve low latency because high bandwidth efficiency is not demanded. The details of the three-step DBA method are explained as follows.
The DBA cycle, TDBA, is expressed as
where Trep and Tdata represent the time for sending REPORTs and the time for sending user data, respectively. Trep depends on the number of linked ONUs, N (N = 1,2, …). It is expressed as
where BOH represents the burst overhead time, which is determined by the optical transceiver ON/OFF time and the sync time. It is fixed. In the initial configuration of our DBA, Tdata_max, four kinds of priority (a > b > c > d), and the GBn for each ONU are set. Here, Tdata_max represents the maximum length of Tdata. We can set an arbitrary length of Tdata_max according to the system requirements. After the configuration has been set, when REPORTs including accumulated data in ONUs come to the OLT, the grant processor starts to allocate a time slot for each ONU in Tdata as shown in Fig. 3. First, as shown in Fig. 3(a), the grant processor calculates RBn using the accumulated data and allocates a shorter time that is equivalent to the GBn or RBn for each ONU. The allocated time, namely, the grant length for each ONU (GL1n) is expressed as
where Rmax represents the effective maximum throughput between the OLT and ONUs, excluding the overhead of line coding. The above allocation enables each ONU to always acquire the guaranteed bandwidth or more in one period of the DBA cycle. When the sum of RBn for each ONU is larger than the sum of GBn, the allocation is finished and the GBn is allocated for each ONU. In contrast, when the sum of RBn for each ONU is smaller than the sum of GBn, unallocated bandwidth (ΔUBm, m = 1,2, …, where m represents the number of iterations until ΔUBm = 0) is derived from the delta between the sum of RBn and GBn. Then, the second allocation starts in Fig. 3(b). The grant processor allocates the ΔUBm for each ONU requesting more bandwidth, in descending order of priority. This achieves priority control among ONUs. The second grant length for each ONU (GL2n) is expressed as
When the grant processor finishes allocating all unallocated bandwidth, the second allocation ends, which is for high-traffic-load cases. The grant length eventually conveyed to ONUs by GATEs is expressed as
TDBA in the high-traffic-load case is expressed as
The latency is determined as the maximum latency that has been set as an initial configuration. In contrast, in the low-traffic-load case, excess bandwidth (ΔEB) is generated after all ΔUBm allocations. ΔEB is expressed as
Then the third step starts. The grant processor subtracts the time equivalent to ΔEB from Tdata_max. As a result, TDBA in the low-traffic-load case is expressed as
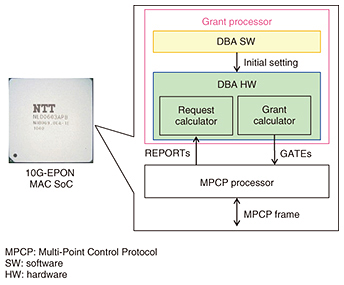
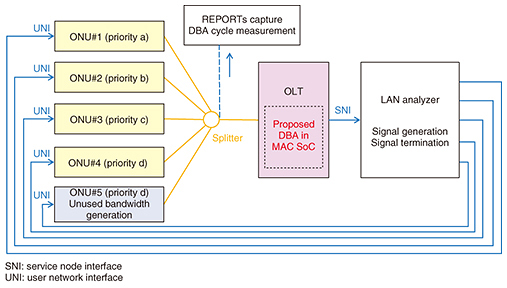
The proposed DBA algorithm is appropriate for implementation in HW because the simple calculations for three-step bandwidth allocation from Eqs. (1) to (11) are repeatedly executed in each DBA cycle. Therefore, it can greatly shorten the Tdata_max length after the second step of allocation. 3. Experimental evaluationWe conducted an experiment in order to evaluate our DBA technique. We describe here the experiment and results. 3.1 Implementation and experimental setupTo evaluate the allocation results and latency, we implemented our DBA function in the grant processor on a 10-gigabit Ethernet passive optical network (10G-EPON) media access control (MAC) system-on-a-chip (SoC) [6] for the OLT as illustrated in Fig. 4. A schematic of the experimental setup is shown in Fig. 5. We utilized a 10G-EPON system with one OLT and five ONUs (ONUs#1–5). The local area network (LAN) analyzer was connected to the OLT-SNI (server node interface) and the ONU-UNI (user network interface) to measure throughput and generate RBn from the ONUs. In this system, ONUs#1–4 were set to measure throughput and the DBA cycle. ONU#5 was set to adjust ΔUB1, which can be generated by adjusting RB5 of ONU#5.
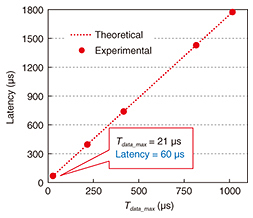
In the experiment, as priorities, “a” was set to ONU#1, “b” to ONU#2, “c” to ONU#3, and “d” to ONU#4 and ONU#5. We set GBn (n = 1–4) at 500 Mbit/s. A burst overhead time was set to 3280 ns. Upstream Ethernet-frame data of 1518 bytes were transmitted from the LAN analyzer at 1000 Mbit/s, which is equivalent to RBn (n = 1–4). We adjusted ΔUB1 using ONU#5. To measure the DBA cycle, we captured REPORTs from ONU#1 and investigated the received interval, which is equivalent to the DBA cycle. First, to confirm the minimum latency utilizing the proposed DBA, we calculated the maximum latency from the measured DBA cycle in the high-traffic-load case when Tdata_max was set to 21, 216, 416, 816, or 1016 μs. The latency in the TDM-PON system is theoretically nearly equal to 1.5 DBA cycles [7]. Next, we confirmed the priority control by adjusting the unallocated bandwidth using ONU#5 and measuring throughput for ONUs#1–4 after DBA allocation. Finally, we confirmed the automatically adjusted function by investigating the change in DBA cycle length when ΔUB1 was adjusted. Tdata_max was set to 1000 μs so that the initial bandwidth efficiency would be more than 95%. 3.2 Measured resultsThe maximum latency calculated from the DBA cycle measurement is shown in Fig. 6. The result of the DBA cycle measurement matches the theoretical value. One can see that when the minimum setting of Tdata_max was 21 μs, the minimum latency of 60 μs was achieved. This is because most of the processing of our DBA is handled by HW.
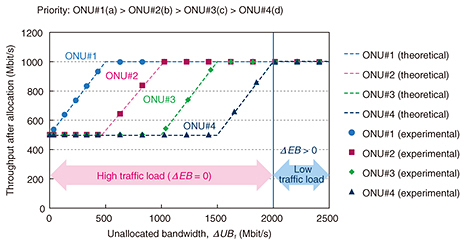
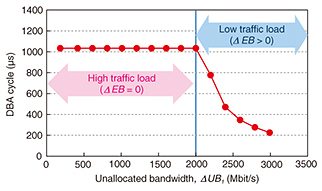
The results of measuring throughput and DBA cycle are plotted in Fig. 7 and Fig. 8. The throughput results match the theoretical values. When ΔUB1 = 0, in other words, when the sum of RBn (n = 1–5) was larger than the sum of GBn (n = 1–5), all ONUs were allocated the guaranteed bandwidth of 500 Mbit/s. When ΔUB1 > 0 but ΔEB = 0, that is, in the high-traffic-load case, ΔUB1 was allocated to ONU#1 first, because its priority was the highest among the ONUs, and its throughput reached 1000 Mbit/s of RB1. After that, ΔUB1 was allocated in descending order of priority. The length of the DBA cycle stayed constant. On the other hand, when ΔEB > 0, that is, in the low-traffic-load case, the throughput stayed constant at 1000 Mbit/s. The length of the DBA cycle automatically decreased as ΔEB increased. These results indicate that our method can automatically adjust the DBA cycle length depending on the traffic load. When the initial Tdata_max was set to 21 μs in the low-traffic-load case, our DBA achieved low latency with high bandwidth efficiency.
4. ConclusionWe proposed a DBA method with an adaptive DBA cycle depending on traffic load for a TDM-PON that accommodates future campus-LANs or 5G MFH. The results of experiments showed that the minimum latency was 60 μs or less owing to simple three-step allocation and cooperation with HW on a 10G-EPON MAC SoC. Moreover, they demonstrated that our method automatically adjusts the DBA cycle length and the bandwidth efficiency depending on traffic load. These results show that our DBA can be used in various networks employing TDM-PON, such as future campus-LANs and 5G MFH. References
|
||||||||||||||||