|
|||||||||||||||||||
|
|
|||||||||||||||||||
       |
Feature Articles: Cognitive Foundation® for Innovative Optical and Wireless Network (IOWN) Vol. 18, No. 6, pp. 21–25, June 2020. https://doi.org/10.53829/ntr202006fa3 Intelligent Zero-touch OperationAbstractNTT laboratories have been researching and developing zero-touch operation technology to reduce and level out maintenance operations for network services. This article describes use cases of intelligent zero-touch operation incorporating artificial intelligence (AI) and introduces three elemental AI technologies used in these use cases. Keywords: zero-touch operation, AI, maintenance automation
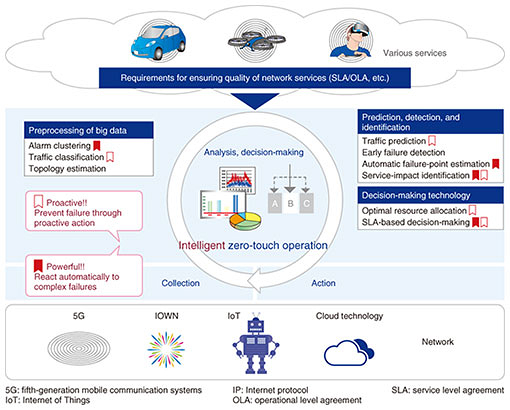
1. IntroductionAs part of NTT’s Innovative Optical and Wireless Network (IOWN), NTT laboratories aim to develop Cognitive Foundation® for coordinating the collection, processing, recording, and communication of data dispersed around a variety of hubs in multiple domains while providing a functional group essential to service deployment and operation. This article introduces our efforts in developing the technologies essential to Cognitive Foundation. In current network operations, alarms occurring due to a failure or quality degradation require operation personnel to analyze and decide on a response such as changing the configuration and replacing defunct network equipment. Services and their required quality are becoming increasingly diversified, leading to increasingly complex operations, even though the number of experienced operation personnel is decreasing. Under such circumstances, reducing the workload is a pressing issue. Against this background, with an eye to the IOWN era, NTT laboratories have undertaken research and development of intelligent zero-touch operation with which artificial intelligence (AI) takes over the analysis and decision-making tasks traditionally carried out by operation personnel then automatically executes a range of processes from information collection to failure response (Fig. 1). As elemental technologies for intelligent zero-touch operation, NTT laboratories have thus far established network resource management technology [1], which can be used with various AI technologies, and federation engine technology [2], which coordinates the processes of information collection, analysis, decision-making, and response. We are also focusing on various AI technologies that perform advanced analysis and decision-making to automate more complex failure response.
2. Traffic classification and prediction technologyThe recent diversification of user terminals and services is creating fluctuations in network traffic all the more complicated. Because of this, traffic prediction has become increasingly difficult. The traffic classification and prediction technology [3] developed by NTT laboratories classifies traffic having similar features into clusters and predicts with high accuracy complex fluctuations in traffic based on the features of each cluster. Clustering traffic with similar features into clusters based on transmission source, transmission destination, transmission time, and amount of transferred data using non-negative tensor factorization—a time-series clustering technique—is a key feature of this technology. It can be used to accurately predict the occurrence of congestion on each link and mount a proactive response. 3. SLA-based decision-making technologyIn addition to advanced data-analysis technology, zero-touch operation requires technology for automating the decisions that have to be made for mounting a problem response. Some examples are whether a response is needed at the time of quality degradation, what failure should be prioritized, when the response should be scheduled, and which response method and by whom are optimal from the point of view of response costs. Service level agreement (SLA)*1-based decision-making technology focuses on the fact that the fundamental objective of network operations is to maintain service quality. This technology automatically makes decisions for mounting a response by evaluating the information indicating service quality (failure duration, average traffic latency, jitter, loss, etc. for each service and user) based on the service quality that must be satisfied (values specified in the user SLA and in-house operational level agreement (OLA)*2 by stakeholders). Application examples of this technology include (1) automatic decision-making on the need for taking action based on predictions regarding service/user SLA violations at a bottleneck point, and (2) automatic decision-making on optimal dispatch timing by comparing the cost of dispatching maintenance personnel to the failure site according to a time slot with increase in losses incurred by SLA violations when delaying response time [4].
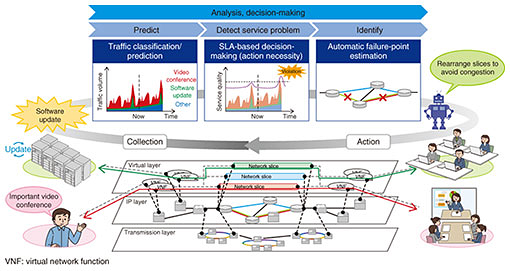
4. Automatic failure-point-estimation technologyThe occurrence of a failure in a large-scale network triggers a large number of and various alarms that make the troubleshooting of failure points workload-intensive. Failure-point-estimation technology [5] infers failure points using rules automatically generated beforehand and visualizes the candidates on a topology map, thereby speeding up network maintenance tasks and reducing workload (and operating costs). Specifically, this technology collects alarms and other events generated at the time of past failures plus their failure points and root causes, derives associations beforehand based on the degree of similarity in combinations of the above, and automatically learns and generates appropriate failure-point-estimation rules. This makes for immediate estimation of failure points even in the case of complex failures. The automatic generation of rule conditions contributes to the formalization of failure-troubleshooting rules that have traditionally relied upon the skills and experience of operation personnel. 5. Use case: proactive responseFigure 2 shows a use case of combining the three elemental technologies described above to mount a proactive response to degradation in service quality caused by congestion. This case involves a time slot for making a major software update that overlaps the time of an important video conference. If no responses are to be taken, the quality of each service would degrade due to congestion, and this important video conference would suffer transmission interruptions.
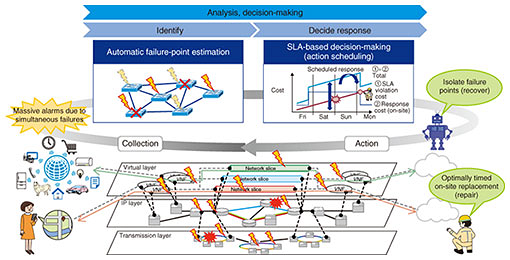
In this use case, our traffic classification and prediction technology predicts with high accuracy traffic fluctuation for each service. Next, SLA-based decision-making technology first predicts the quality of each service and estimates SLA violations in the video conference, then determines the necessity of maintenance responses and issues alarms if needed. Finally, automatic failure-point-estimation technology infers failure points and causes from all the alarms generated during this period. In this case, no failure alarms other than SLA violation alarms would have been generated, so this technology would use rules formulated beforehand to estimate the root cause as a simple congestion (not congestion due to a failure) and to estimate the failure points associated with the (inferred) root cause. Finally, quality degradation in the video conferencing service can be avoided by proactively changing the network route of the software-update service to prevent SLA violations. This type of proactive response can be carried out without human interaction and without users noticing any degradation in service quality. 6. Use case: response to complex failureFigure 3 shows a use case of a response to a complex failure that generates a large number of alarms from multiple layers on the network due to the simultaneous occurrence of multiple failures. In this case, information related to these failures on different layers would be displayed together on a monitoring screen, which increases the workload of operation personnel since they would have to analyze these data.
In this case, automatic failure-point-estimation technology would first learn about the alarms that characterize failures from past cases and immediately estimate failure points and root causes using the generated alarm group. This technology can visualize the effects of failures spanning different layers by performing data management using network resource management technology [6]. Next, a traffic route is diverted to avoid failure points. This would recover services, but in the event of equipment failure, the entire system would not be recovered until maintenance personnel arrive at the site and replace the defunct equipment. For this reason, SLA-based decision-making technology would evaluate work costs and losses incurred by SLA violations using common indices to decide on the optimal on-site work period (for example, “Should this work be done immediately?” “Can it be done tomorrow or later without upsetting the customer?”). This technology automates the work of responding to a complex failure that requires a heavy workload, reduces that workload, and improves service quality. 7. Future outlookThis article introduced three elemental AI technologies for achieving intelligent zero-touch operation and use cases of proactive response to complex failures applying these technologies. NTT laboratories will continue to work on researching and developing various AI technologies, expand the automation domain, coordinate various AI technologies, and enable practical use of intelligent zero-touch operation. References
|
||||||||||||||||||