|
|||||||||||||
|
|
|||||||||||||
       |
Feature Articles: Toward More Robust Networks Vol. 21, No. 12, pp. 17–23, Dec. 2023. https://doi.org/10.53829/ntr202312fa1 Operation to Achieve Robust NetworksAbstractLarge-scale communication-infrastructure failures have a tremendous impact on daily life and economic activities, requiring more resilient networks. We at NTT laboratories aim to achieve robust networks that minimize service impact by improving network adaptability to system failures and shorten recovery time by improving network resilience. This article describes our research and development efforts in operation-related technologies to achieve robust networks. Keywords: robust network, operation, NW-AI
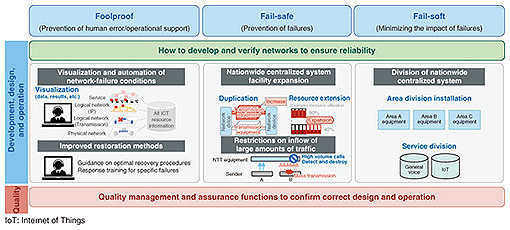
1. Toward robust networksNetwork operations are becoming increasingly complex due to virtualization technologies, complex network configurations with commercial products, and the vast amount of data distribution caused by the diversification of services. Information and communication technology (ICT) has been widely used in various areas of social and economic life, and large-scale communication-infrastructure failures will have a tremendous impact on people’s daily lives. Therefore, more resilient networks are required. We at NTT laboratories have been conducting research and development (R&D) to achieve robust networks that are highly resilient to network-system failures and large-scale disasters. This article introduces our R&D efforts focusing on operation technologies to enhance network-system fault tolerance. 2. Countermeasures against communication-infrastructure failuresThere are various causes of communication-infrastructure failures, such as chain failures due to software failures, abnormal traffic, operational errors, and system anomalies. As network systems become more complex, diverse, and virtualized, and as the use of vendor-specific products leads to black boxes inside the systems, it is expected that countermeasures based on an understanding of equipment implementation and prior verification of assumed failure events based on past cases will no longer be sufficient to cover all types of failures. Therefore, to achieve a robust network, we discuss operation-related technologies from the viewpoints of foolproof, fail-safe, and fail-soft as a basic policy for communication-infrastructure failure countermeasures based on the assumption that unexpected events are bound to occur (Fig. 1).
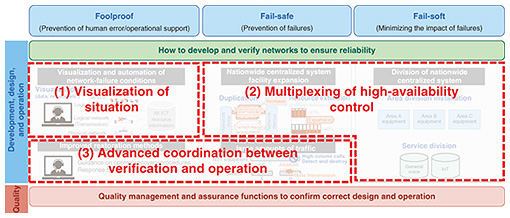
To ensure the reliability of network systems, it is necessary to consider countermeasures in each work phase of development, design, and operation on the basis of the above three viewpoints. Network quality control and assurance functions should also be considered to monitor the correctness of the considered countermeasures in designs and operations. To enhance network-system-failure resilience, we will research and develop new technologies in the following three directions to minimize unexpected events in response to the increasing complexity, diversity, and virtualization of network systems, which are making network operations more difficult (Fig. 2).
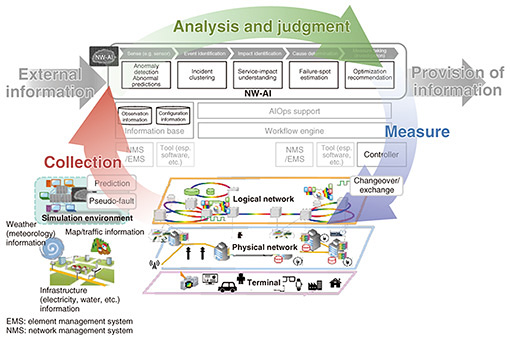
(1) Visualization of situation To take early countermeasures when a communication-infrastructure failure occurs, it is important to understand the network status and be able to identify the failure location and factors. Therefore, we aim to develop technologies that intelligently visualize the status of the network by using various types of information that can be obtained both inside and outside the network, in addition to logs, alarms, and other information output from the network devices that are dependent on the device implementation. (2) Multiplexing of high-availability control To maintain system availability and reduce the risk of failures, it is important to have a variety of remedial measures for network systems. We aim to prevent communication-infrastructure failures and minimize service impact by implementing high-availability control technologies that provide multifaceted remedial measures without limiting the system or service. (3) Advanced coordination between verification and operation When service operations encounter unexpected events, it is difficult to deal with them at earlier stages, so it is important to minimize such events in advance during system verification. Network systems are becoming more complex with the use of virtualization technology and vendor-specific products, and services are also becoming more diverse. Therefore, various events are affecting each other in complex ways at a level far beyond human knowledge, resulting in the occurrence of unexpected events. System verification based on experience makes it difficult to reduce unexpected events. Therefore, we adopt an approach that drastically changes the traditional experience-based verification method by using a digital-twin environment of devices and networks. With this verification method, the artificial intelligence (AI) extracts all verification conditions, generates simulated failures in a digital-twin environment on the basis of the extracted conditions, and the other AIs autonomously learn recovery countermeasures. These AIs are then applied to actual operations in a timely manner to achieve advanced coordination between verification and operation. The new technologies to be created in these directions will improve the adaptability to network-system failures, minimize service impact, and improve resiliency to achieve robust networks with shorter recovery times. In network operations, which are becoming increasingly difficult due to the growing complexity of network systems and the vast amount of data being distributed, we aim to achieve automated and autonomous operations in the future by proactively using AI. 3. Visualization of situationAs network systems become increasingly complex and black boxed due to virtualization technology, early detection of anomalies is important. Preventing human error and providing effective support are also important from the perspective of foolproof operation. We aim to solve these problems using AI and achieve self-evolving zero-touch operations that will automate and autonomously operate networks in the future. An AI used in network operations is called an NW-AI, and the flow of self-evolving zero-touch operations using an NW-AI is shown in Fig. 3. The NW-AI first collects configuration and observation information inside the network and various information outside the network, such as weather, social media, and local events. It next analyzes the collected information and determines the next action. On the basis of the results of the decision, it then executes actions on the network system. By automatically repeating this closed loop and developing an NW-AI that learns autonomously, we aim to achieve self-evolving zero-touch operations.
The process of analysis and decision making by an NW-AI enables visualization of network and service conditions. When failures occur, the NW-AI first detects anomalies and their predictive signs by making more multifaceted judgments on the basis of alarms from the system, traffic fluctuations, and information from peripheral devices and outside the network. It next identifies the event and the range of service impact caused by the failures. It then estimates the failure locations and identifies the causes of failures. Traditionally, visualization of these conditions has been manually analyzed by operators using large numbers of alarms output at each layer, such as the physical network layer, logical network layer, and service layer. However, this has taken a long time to gain complete visibility of the situation. Development of an NW-AI that supports and automates these tasks is expected to enable early detection of failures. We are currently developing several NW-AI technologies, i.e., DeAnoS™ (Deep Anomaly Surveillance) [1], which models the normal state of systems from various data using deep learning and detects anomalies on the basis of deviations from the normal state; alarm clustering, which aggregates alarms from systems into event units; NOIM (Network Operation Injected Model) [2], which visualizes the service-impact range of failures; and DeAnoS-RCA (Deep Anomaly Surveillance-Root Cause Analysis) and Konan (Knowledge-based autonomous failure-event analysis technology), which estimate failure locations, etc. These technologies are introduced in the article “Technologies for Promptly Understanding Network Conditions When Large-scale System Failure Occurs” [3] in this issue. 4. Multiplexing of high-availability controlTo improve service availability in the event of communication-infrastructure failures, current network systems have taken measures such as equipment redundancy and high-volume traffic-flow control. However, early failure recovery may be difficult even with current countermeasures. Therefore, the issue is to ensure numerous remedies on the basis of the assumption that unexpected events will occur. Although the implementation of multiple remedies can improve the reliability of the system, it is expensive, making it difficult to evaluate the balance between reliability and economic efficiency. The mechanism to being considered to minimize the service impact in the event of failures is fail-soft. For example, devices can be divided and strengthened in areas or by service providers to prevent a single-device failure from spreading to other areas or services. As a fail-safe mechanism to prevent failures from occurring and enable early recovery from failures, redundancy of devices and functions in network systems is being considered. It is expected that network virtualization will make it possible to secure system redundancy more economically in the future. Resource multiplexing, layer multiplexing, network service multiplexing, etc. are being considered as redundancy mechanisms to increase high availability of services. Regarding resource multiplexing, resources in a virtualized and distributed system required for each service and spare resources for redundancy are optimally allocated in advance from the hardware-resource pool. When an anomaly occurs and spare resources are insufficient, emergency resources for escaping from the anomaly spiral or resources already allocated to other services are temporarily allocated. Mechanisms for sharing and isolating hardware resources are also being considered to reduce interference between services. In layer multiplexing, the independence of each network layer, such as transport networks, Ethernet networks, and Internet Protocol (IP) networks, is maintained under normal conditions, and optimal control is executed by inter-layer collaboration when failures occur. Redundant design and control are carried out in consideration of the dependencies among layers, and mechanisms to deter anomalous external events at the optimal layer are being considered. In network-service multiplexing, mechanisms to prevent the occurrence of total large-scale failures through the multiplexing of various network services are being considered. Examples include access network multiplexing, in which wireless access is switched to other systems in the event of an anomaly, and core network multiplexing, in which network slices and optical paths are switched in consideration of the quality-of-service level in the event of an anomaly in a virtualized network. Specific technologies for network service multitasking, transmission-network redundancy, etc. are introduced in the article “Network Reliability Design and Control Technology for Robust Networks” [4] in this issue. 5. Advanced coordination between verification and operationWhen various services are provided, various verification tests are conducted in the development and construction of devices and systems. However, it is difficult to cover all failures in network systems, which are increasingly complex and black boxed due to virtualization technology and other factors. Therefore, the challenge in network operations is to find ways to handle events that exceed the assumptions of device developers and system designers. Another challenge is to create a network-operation framework that eliminates human error and efficiently handles unexpected events. We are studying a framework for advanced coordination of verification and operation by using the digital-twin environment and verification environment. This framework is shown in Fig. 4. First, an environment simulating network systems with commercial services is constructed on a digital twin or verification environment. In the simulated environment, variations of failure events are artificially generated using chaos-engineering tools that generate pseudo-failures. Therefore, the possibility of extracting unexpected events is increased. The goal is to develop an NW-AI that can autonomously recover from failure events. The key points of technical development are as follows.
(1) Event generation Verification conditions, such as failure events, are generated artificially by using an NW-AI. These verification conditions are efficiently generated on the basis of the analysis results of traffic-data flows in commercial services. (2) Verification and AI learning using chaos engineering Failure events based on the generated verification conditions are generated in a simulated environment using a chaos-engineering tool. Thus, the system’s behavior under conditions that are out of the scope of the equipment developer’s or system designer’s assumptions can be understood. By autonomously learning system behavior and countermeasures in the simulated environment, an NW-AI can cope with unexpected events in a commercial-service environment. The learning of system behavior and countermeasures in the simulated environment is not limited to training of the NW-AI but also intended to be used for training network operators. (3) Model and data transfer The simulated environment is assumed to be a verification environment for service development or a digital-twin environment built with digital technology. The higher the similarity, the more similar the verification to commercial services. However, since it is difficult to perfectly match the commercial and verification environments, transfer technologies are required to apply the NW-AI models and data learned in the simulated environment to the commercial environment. Details of this framework are introduced in the article “NW-AI Self-evolving Framework for Fault-tolerant Robust Networks” [5] in this issue. 6. Future developmentsThis article introduced R&D efforts in operation-related technologies for robust networks. We aim to achieve more resilient networks against communication-infrastructure failures and disasters and the operations that support them by implementing the technologies in the R&D stages described in this article. We will also accelerate R&D on an NW-AI to achieve self-evolving zero-touch operations that will automate and autonomously operate networks in the future. References
|
||||||||||||