|
|||||||
|
|
|||||||
|
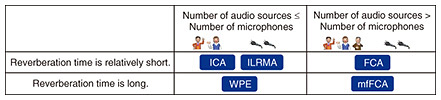
Front-line Researchers Vol. 23, No. 5, pp. 1–5, May 2025. https://doi.org/10.53829/ntr202505fr1  Undertaking Research on Audio Source Separation and a Method for Training Hardware-oriented Neural Networks by Using Algorithms That Exploit Correlations and Complex NumbersAbstractOptimization problems involve expressing the problem to be solved as a mathematical formula and finding the best solution from all feasible solutions. They are used to solve a wide range of problems, such as creating shift schedules that even out work frequencies and times of employees and determining the optimum production volume of a product to maximize profits, and there are a variety of approaches to solve them. As artificial intelligence (AI) becomes more prevalent, more opportunities to use AI to solve optimization problems will arise. Optimization problems are also applied to machine learning in AI. Hiroshi Sawada, a senior distinguished researcher at NTT Communication Science Laboratories, has been achieving new results by incorporating a long-standing optimization method into his research on two themes: audio source separation and a method for training hardware-oriented neural networks. We spoke with him about his research approach and results concerning these themes as well as the importance of building connections with other fields on the basis of one’s technical expertise. Keywords: audio source separation, multi-frame full-rank spatial covariance analysis (mfFCA), hardware-oriented neural network  Applying the natural gradient method used in research on audio source separation to a method for training hardware-oriented neural networks—Would you tell us about the research you are currently conducting? I’m conducting research on audio source separation and a method for training hardware-oriented neural networks. I have been researching audio source separation for about 20 years. In my previous interview (May 2022 issue), I discussed audio source separation using independent low-rank matrix analysis (ILRMA), which integrates non-negative matrix factorization for capturing the structure and characteristics of information sources such as data and signals, and independent component analysis (ICA) for estimating how data and signals are observed with sensors through an observation system. I also talked about being selected in 2022 as one of the IEEE (Institute of Electrical and Electronics Engineers) Signal Processing Society Distinguished Lecturers (for a two-year term), in which five lecturers are selected each year per field. Due to the COVID-19 pandemic, the lectures were only held in 2023, and I gave a lecture, including a live demonstration, on ILRMA at research institutes in Australia, New Zealand, and Germany. In Germany, many authoritative researchers in the field of acoustic signal processing attended, and the lecture was very well received; in fact, the question-and-answer session lasted over 30 minutes. ILRMA separates audio sources in situations where the number of microphones picking up the sound is equal to or greater than the number of audio sources and the reverberation time of a room is relatively short. Subsequently, my research colleagues and I proposed a new method of audio source separation called multi-frame full-rank spatial covariance analysis (mfFCA), which is effective in situations where the number of audio sources is greater than the number of microphones and the reverberation time of a room is long. I presented mfFCA at the International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2022, and the paper was published in IEEE/ACM Transactions on Audio, Speech, and Language Processing [1]. As shown in Fig. 1, I had been working on methods for audio source separation, such as ICA, ILRMA, and FCA, that are effective in situations where the reverberation time is relatively short. NTT Communication Science Laboratories is home to Senior Distinguished Researcher Tomohiro Nakatani and his colleagues, who have been researching and developing a method of removing reverberation called weighted prediction error (WPE). In collaboration with them, we were able to take on the challenge of audio source separation for situations where the reverberation time is long and propose mfFCA, which models reverberation by focusing on the correlation between frames with different times.
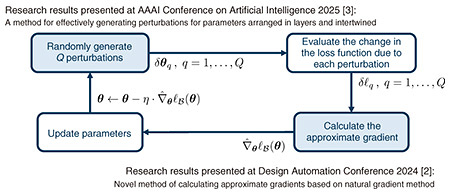
—What is involved in your research on the theme “a method for training hardware-oriented neural networks”? A neural network is generally trained (i.e., machine learning) using a machine-learning algorithm called “backpropagation.” Backpropagation involves propagating the error between the output and target values backwards in each input, hidden, and output layer of a neural network and adjusting the weights applied to each layer to efficiently generate an output that is close to the target value (thus, the performance of the neural network is improved). Backpropagation enables neural networks to recognize complex patterns and achieve functions such as prediction and classification. The increasing power consumption of neural networks has become a serious issue, and it is expected that this issue can be addressed by implementing neural networks in hardware such as optical devices. However, hardware has inherent characteristics that vary due to variation in manufacturing and slight changes in temperature, and these variation and change in characteristics degrade the accuracy of backpropagation. My research theme of a method for training hardware-oriented neural networks is to address such situations in which the general training method (i.e., backpropagation) is ineffective. One approach is zeroth-order optimization (ZOO), with which parameters are gradually changed (perturbed) from their initial state during training into the direction that produces “good” results, namely, reduces the loss function. The procedure of ZOO is shown in Fig. 2. First, a certain number (Q) of perturbations is generated. Next, for each perturbation, the amount of change in the loss function is evaluated using a neural network implemented in hardware. Once the perturbations and their evaluation values are known, an approximate gradient can be calculated, and the parameters can be updated on the basis of the gradient. Training of the neural network proceeds by repeating this loop.
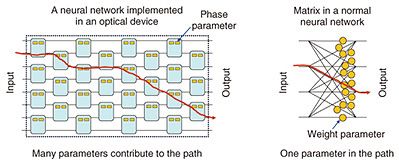
The parameters of a normal neural network are arranged in the form of a matrix, and calculations are executed by multiplying this matrix by intermediate vectors to obtain further vectors. However, when a neural network is implemented directly in hardware, for example an optical device, any unitary matrix (extending an orthogonal matrix with real numbers to one with complex numbers) can be implemented by continuously shifting the phase of light as a parameter, and calculations with larger unitary matrices can be executed by expanding each unitary matrix in a planar and layered manner. These parameters obviously differ from those used in the usual matrix format. A particular challenge is that the parameters are arranged in layers; thus, many parameters contribute to the light path and are intertwined (Fig. 3).
As the first result of this theme, I devised a method for calculating approximate gradients based on the natural gradient method and presented it at the Design Automation Conference (DAC), a leading conference in the field of electronic design automation, held in San Francisco, USA in June 2024 [2]. The natural gradient method is an optimization algorithm and insensitive to the structure in which the parameters are arranged; it thus improves efficiency and accuracy in regard to training neural networks implemented in optical devices. I have used the natural gradient method as a standard method when working on ICA for audio source separation This method has recently been used for training normal neural networks that use backpropagation. I thought that it might be possible to use this method for training a hardware-oriented neural network with ZOO, so I began my research on that possibility. When we try to use the natural gradient method to train a normal neural network, it is necessary to calculate the inverse of a huge matrix equal to the square of the number of parameters. However, this calculation becomes impossible when the number of parameters is more than a few thousand, so several approximation methods have been proposed. In contrast, we proposed a method with which the size of a matrix to be inverted is the square of the number Q of perturbations. In practice, Q is up to several hundred, so the calculation can be executed with little computational overhead. After the proposal of mfFCA, the focus of my research activity shifted from audio source separation to a method for training hardware-oriented neural networks, but I am continuing to teach machine learning at an in-house technical course, which was introduced in the previous interview, to foster the next generation of researchers for new employees and employees in their third year of employment. Now in its eighth year, the course covers content that has remained almost the same for the past few years (although the recent boom in generative AI is touched upon in the introduction). Perhaps because the explanations are consistent and easy to understand, the course has been well received by those employees, who made comments such as “I was able to listen to essential explanations and in-depth content.” By teaching machine learning, I have gained a much deeper understanding of neural networks and have obviously put this understanding to good use in my current research. —You have recently achieved new results and presented them at an international conference, right? Yes, our paper submitted to the Association for the Advancement of Artificial Intelligence (AAAI), the prestigious scientific society in the field of AI, was accepted in December 2024, and I presented it at the AAAI Conference on Artificial Intelligence held from February 25 to March 4, 2025 [3]. The presented results correspond to “Randomly generate Q perturbations” in Fig. 2. With ZOO, random perturbations are typically generated from a multivariate normal distribution, which is effective when the parameters are highly independent. However, as I mentioned earlier, since the parameters used in an optical neural network are intertwined, I realized that we should also take into consideration what kind of randomness should be used to generate the perturbations. With that consideration in mind, we devised a method for calculating the correlations between all parameters of a unitary matrix structured in a planar and layered manner and applying perturbations to the matrix to cancel out the correlations. Identify core areas of your technical expertise and make connections with people in other fields to produce results—What do you keep in mind as a researcher? The field of my research has shifted from design automation of digital computers to audio source separation then hardware-oriented optical neural networks. During this time, serving as head of research and planning, I had the opportunity to learn about other research that was outside my specialty. I want to base my research on core areas of my technical expertise and be involved in those areas in some way as much as possible. When conducting research in a completely different field, you may feel anxious about whether you will be able to produce results. However, if the common core technology is used in different fields, such concerns can be alleviated. In terms of common core technologies, for example, the aforementioned design automation, audio source separation, and optical neural networks all use algorithms that exploit correlations and complex numbers. When encountering a topic that interests me, I identify common technologies between the topic and my current theme then use those technologies as the basis for setting my next theme. In other words, since the starting point of my field of interest is common technologies, my research themes to date have ended up being connected by common technologies. I also want to be conscious of connecting with people in different fields and collaborate with them when possible. Over the past decade or so, AI, big data, and machine learning have been attracting attention and are now being used in a variety of fields. While conducting research on signal processing and machine learning, I have also participated in colloquiums involving different research laboratories at NTT. If my research remained focused on signal processing and machine learning, I would be limited to simply manipulating mathematical formulas relating to correlations and complex numbers; however, by exchanging opinions and discussing topics with people in applied fields at those colloquiums, I was able to gain much insight into the application of my research. Recently, colloquiums on such topics as speech acoustics, language, heart-touching AI, and human research have been launched simultaneously in a cross-laboratory manner, and I am pleased to see the results of those discussions. I have organized colloquiums in the past, but you don’t always have to initiate them; it is just as important to participate in ones in areas that interest you. Build complementary and cooperative relationships based on your areas of expertise and lead your research in the right direction—What is your message to younger researchers? As I mentioned in the previous interview, although it is extremely difficult to have a paper accepted at an international conference, it is important to keep trying. Moreover, when you work as a researcher for a long period, it is common to change your research theme rather than staying focused on the same theme. I also believe that collaborative research with people from other fields will become crucial in the future and that opportunities for it will increase. At such times, it is important to have core areas of expertise that will position you in a place from which you can excel in new fields. It is fully expected that technology fields will be further subdivided. In this environment, few will be “super researchers” who can fully demonstrate their abilities in all fields. Therefore, I believe it is important to build a complementary and cooperative relationship with other researchers through which each researcher shows their areas of expertise, which will create a synergistic effect that will advance your research in the right direction. References
■Interviewee profileHiroshi Sawada received a B.E., M.E., and Ph.D. in information science from Kyoto University in 1991, 1993, and 2001. He joined NTT in 1993. His research interests include statistical signal processing, audio source separation, array signal processing, machine learning, latent variable models, graph-based data structures, and computer architecture. From 2006 to 2009, he served as an associate editor of the IEEE Transactions on Audio, Speech and Language Processing. He received the Best Paper Award of the IEEE Circuit and System Society in 2000, the SPIE ICA Unsupervised Learning Pioneer Award in 2013, the Best Paper Award of the IEEE Signal Processing Society in 2014, and the APSIPA Sadaoki Furui Prize Paper Award in 2021. He was selected to serve as an IEEE Signal Processing Society Distinguished Lecturer for the term 1 January 2022 through 31 December 2023. He is an IEEE Fellow and IEICE Fellow. |
|||||||