|
|||
|
|
|||
       |
Rising Researchers Vol. 23, No. 6, pp. 8–11, June 2025. https://doi.org/10.53829/ntr202506ri1  Expressive Speech-synthesis Technology Supports People’s Daily LivesAbstractSpeech-synthesis technology improves accessibility for people with disabilities and the elderly and supports peoples’ daily lives in applications such as call centers and car-navigation systems. It is currently being used in applications such as automatically generating narration, game-character voices, and voices in multiple languages while preserving the tone of voice. Speech-synthesis technology can be used not only for creating voice actors and celebrity voices but also to restore the voices of people who have lost their voice for some reason, if audio or video of them is available. It can thus greatly contribute to society, but challenges in making synthesized speech sound more natural remain. We spoke with Distinguished Researcher Yusuke Ijima, who developed the latest speech-synthesis technology, “zero/few-shot cross-lingual speech synthesis.” Keywords: speech-synthesis technology, tone of voice, cross-lingual speech synthesis
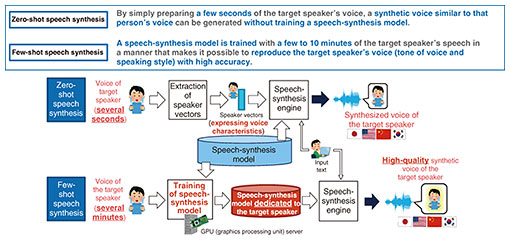
Zero/few-shot cross-lingual speech synthesis can synthesize speech similar to that of a person by using only a few seconds of recorded data—Would you tell us what kind of research you are currently conducting? As a media-conversion technology, speech synthesis converts text into speech in a two-step process: text analysis, which adds readings and accent, and speech generation, which creates intonation, tone of voice, and speech waveforms. I have been researching speech processing ever since my student days. At that time, I was researching speech recognition, which converts speech into text and speech-emotion recognition, which recognizes the emotions contained in speech. Since joining NTT, I have been researching speech-synthesis technology. Although speech synthesis has been investigated for a long time, recent technological advances have made it possible to generate synthetic speech that sounds more natural than before. Speech-synthesis technology is widely used in services for accurately conveying information to users. Such services include safety confirmation used during natural disasters (such as Web171), telephone information such as guidance from call centers, and car navigation. Recent technological advances in large language models and speech synthesis have led to increased demand for entertainment applications and interactive services with characters. In conventional services for accurately conveying information, it has been sufficient to be able to generate the voice of a specific pre-defined speaker. However, in recent services for such applications, it is also important to be able to reproduce a voice that meets the needs of the content creator at low cost and with high accuracy. With the general method of speech synthesis, if the request is to “create speech that reproduces a certain person’s voice,” the person’s voice is recorded, pronunciation (readings, accent, etc.) is manually added to the recorded voice, and the annotated voice is used to train a speech-synthesis model. However, the costs and lead time required for voice recording and annotation make it difficult to use this method for content production. Against this background, we developed “zero/few-shot cross-lingual speech synthesis” for synthesizing a voice that resembles a person’s voice from just a few seconds of audio without the need to record large amounts of audio or add pronunciation or accents to the recorded audio. By using only a few seconds of voice data, zero-shot speech synthesis can create synthetic speech from a variety of texts in a voice similar to that of a person, and by using only a few minutes of voice data, it can reproduce that person’s tone of voice and speaking styles with greater accuracy than previously possible. This technology can also generate synthetic speech in multiple languages, such as English and Mandarin Chinese, while preserving the person’s tone of voice (Fig. 1).
Using zero/few-shot cross-lingual speech-synthesis technology makes it possible to create robots or artificial intelligence (AI) agents that can respond in the voices of celebrities, such as television personalities and voice actors, or even in the voices of one’s own family members. It will also make it possible for an information-service character to respond in multiple languages to foreign tourists and other non-Japanese speakers without changing the tone of voice from Japanese. Research does not end with technological development; it creates value by having the developed technology actually used—Would you tell us what this research can achieve and what potential impact will it have on society? As a corporate researcher, I think it is important to produce research results; however, I place more importance on putting the research results to practical use and having them actually used by people both inside and outside the NTT Group. Particularly in our field of media processing, which deals with speech, language, images, and other inputs, the boundary between research and practical application is vague, and technological progress in this field is occurring very rapidly. Under these circumstances, we need to approach our research with the mindset that any research that cannot be released to the public should be considered a failure. To ensure that our research results are actually used, it is essential to collaborate with a variety of people both inside and outside the NTT Group. One of these collaborations is recreating the voices of people who have lost their voice due to illness or accident. We are working to see if we can recreate the voices of such people from the faint sounds of their voices contained in home videos and other sources. We are also collaborating with NTT WEST to use this technology for content production. Through this collaboration, we aim to provide services that use characters and the voices of celebrities by collaborating with IP (intellectual property)-rights holders, who hold the rights to characters and other assets, as well as talent agencies. The demand for audio content, such as audio advertisements and audiobooks, has been increasing, and has generated many requests to use the voices of characters and celebrities. However, under the current circumstances, the working hours of such people are limited. We expect that using our cross-lingual speech-synthesis technology will make it possible to virtually increase the working hours and make it possible to create content in multiple languages while preserving the tones of voice of characters and celebrities, which may help characters and other content created in Japan to expand overseas. For other areas of application of our cross-lingual speech-synthesis technology, e.g., call centers, where information has traditionally been provided in standard phrases, we have been asked whether it would be possible to generate synthetic speech that sounds more natural, like that of a phone operator, to improve customer service. —What are the challenges and key points regarding your research? Current speech-synthesis technology is now able to do things that were difficult to do a generation ago, such as generating a voice that sounds similar to a person’s voice from only a few seconds of audio. However, there is a large difference between the expressiveness of synthetic speech and that of the speech of professional voice actors and announcers. I work with such people as part of my job, and each time I do, I am made acutely aware of the difference between expressiveness generated with current speech-synthesis technology and that of professionals. For example, during actual audio recording, the voice actor does not simply read from a prepared script; that is, to record the audio that the sound director or director desires, the voice actor receives instructions on how to express the desired voice and repeatedly modifies the expression accordingly. To achieve the desired voice, they need to understand the intention behind the detailed instructions and reflect this in the voice expression. However, with current speech-synthesis technology, it is extremely difficult to portray such subtle expressions and nuances in the synthesized speech. The technology faces many challenges in terms of the diversity of expressiveness required to grasp the feelings of characters and the relationships between them from a script or novel and express them through speech. Resolving these issues is essential before we can meet the needs of the above-mentioned content production and call centers. While speech-synthesis technology has made it easy to generate a variety of voices, problems such as fake videos using the voices of celebrities taken from the Internet have emerged, making it important to protect the rights of the speaker. A few years ago, celebrities or their agencies had little negative impression about providing a service that uses synthetic speech of celebrities’ voices; however, negative impressions are increasing significantly. To make speech-synthesis technology more widely usable, it is essential to address these concerns from both legal and technical perspectives, so the NTT Group is working on a variety of efforts to address these concerns. NTT Social Informatics Laboratories is conducting research into the rights of speakers from a legal perspective, while NTT WEST is investigating technology to trace speech generated by speech-synthesis technology from a technical perspective. By collaborating with these organizations, we hope to move beyond simply creating speech to advance efforts that also include the protection of rights. —What difficulties do you face from a business perspective? When trying to make speech synthesis a viable business, it is important to consider factors such as running costs. With current speech-synthesis technology, for example, it is possible to improve quality and implement new functions by increasing the model size. However, if hundreds of thousands or millions of people are to use a speech-synthesis service, the maintenance costs of servers and other equipment will be enormous, and it may not be possible to run the service as a viable business. The difficult part is figuring out how to proceed with research and development while considering this balance between model size and cost. To enable our team to release a speech-synthesis product, we must ultimately decide which technologies to adopt in developing the next product when it is time for practical development. To maintain the competitiveness of our product, we need not only technologies that must be adopted but also technologies that can become differentiating factors at the practical-application stage. Our research and development must strike a balance between these factors with a limited number of team members. —What is your message to young researchers, students, and business partners? When working as a corporate researcher, I believe it is important to be aware of whether the work you are doing will produce innovative research results or lead to practical business outcomes. If you are not able to achieve either of those goals, you may need to decide to change the research topic you are working on or the content of your research. In the fields of media processing and AI, the boundary between research and practical application is undefined, and if we let our guard down for even a moment, we tend to do things that have no academic significance or practical application half-heartedly. I also try to be constantly aware of my role and what is expected of me in my job, and I believe it is important to keep that awareness in mind no matter what task I am assigned to. I think the main attraction of NTT is our wide variety of specialized human resources. I specialize in speech processing, but within the company, we have many experts in a variety of fields, including speech processing. When I want to ask someone about a field that differs from my specialty, for example, I can just ask the question, “I want to use this technology in a product, but how do I do that?” via online chat and someone will give me immediate advice. This is an attraction unique to NTT and not available at other companies.
■Interviewee profileYusuke Ijima received an M.E. and Ph.D. in information processing from Tokyo Institute of Technology (currently Institute of Science Tokyo) in 2009 and 2015. He joined NTT Cyber Space Laboratories (currently NTT Human Informatics Laboratories) in 2009, where he engaged in the research and development of text-to-speech synthesis. His research interests include text-to-speech synthesis, voice conversion, automatic speech recognition, and speech analysis. He received the Maejima Hisoka Award, Encouragement Award in 2021. |
||