|
|||||||||||
|
|
|||||||||||
|
Feature Articles: NTT R&D at Expo 2025 Osaka, Kansai, Japan Vol. 23, No. 10, pp. 39–44, Oct. 2025. https://doi.org/10.53829/ntr202510fa4 Another Me Planet—An Alter Ego That Shows Potential Future SelfAbstractAt Expo 2025 Osaka, Kansai, Japan, a Virtual Expo was held where visitors could experience the event 24 hours a day. The Virtual NTT Pavilion provided content linked to a real venue in Yumeshima, Osaka. The pavilion also provided Another Me Planet, which enables people to communicate with themselves in future occupations and realize their potential so that they can experience the world view of Another Me™, a theme of the real venue. This article introduces Another Me Planet and the technology to achieve it. Keywords: Another Me, speech synthesis, large language model  1. Virtual NTT Pavilion linking real and virtualIn addition to a real venue in Yumeshima, Osaka, NTT also exhibited a virtual pavilion at the Virtual Expo of Expo 2025 Osaka, Kansai, Japan [1], which consisted of three different venues (Rooms 1, 2, and 3) in conjunction with the real venue (Fig. 1).
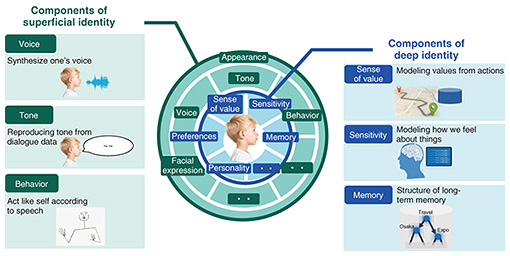
The theme of Room 3 was Another Me™, one of the Grand Challenges [2] of the Digital Twin Computing Initiative proposed by NTT in 2020. Another Me is a digital twin. With Another Me of oneself that can act autonomously, we aim to expand various life opportunities. Another Me in the Virtual NTT Pavilion used the virtual space’s ability to provide content tailored to each user with a high degree of freedom and provided Another Me Planet as a unique application that makes visitors feel closer to the world view of Another Me. The purpose of this application is to expand the possibilities of one’s future by using oneself as a use case and by communicating with Another Me, who has a job in the future that one does not currently have. This article introduces various initiatives for the actualization of Another Me and Another Me Planet. 2. Technologies that make up Another MeIn Another Me, what elements are needed to be able to express oneself? NTT laboratories have been conducting research and development by dividing the elements of “self” into two major layers: deep and surface (Fig. 2). The deep layer is innate or acquired through various experiences and serves as a standard of behavior. We are investigating the structuring of memories on the basis of various experiences, extraction of the axis of values, and extraction of sensibility using brain waves. The surface layer is a way of expressing behavior. In addition to appearance, NTT laboratories are investigating the generation of voice, speech content, and body movement.
By combining the technologies that make up Another Me, we are demonstrating how to use it in various fields. As a new expression by this alter ego, we have been demonstrating a new expression on the stage by Another Me. We have also been demonstrating support for building relationships in virtual space as support for building human relationships with Another Me. 3. Another Me Planet—an application where one realizes their potential by interacting with their future alter egoAnother Me Planet is an application of expanding one’s own potential by visualizing various possible selves through Another Me. Another Me Planet was exhibited at the Virtual NTT Pavilion so that users could experience the concept of “Through Another Me, people achieve their potential and expand various life opportunities” (Fig. 3).
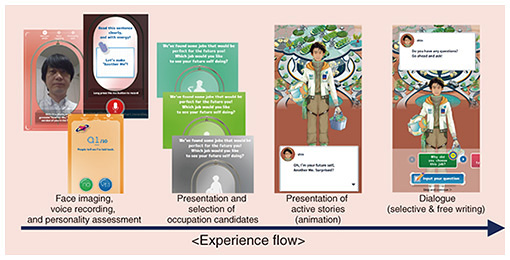
To use the “working self” in one’s life as a use case and to determine one’s potential, Another Me with a job that the user does not currently have but could have in the future will be created. Through interaction with Another Me, people will be able to visualize and realize their potential, which is difficult to do themselves. Figure 4 shows the experience flow of Another Me Planet. The user first takes a photo of their face to generate the appearance of Another Me. To generate the voice of Another Me to sound like the voice of the user, the user is then asked to read a very short sentence that forms the basis of the generated voice. Finally, to give characteristics to the utterances of Another Me, the user answers a questionnaire. On the basis of the above, Another Me with a future job is generated. The user can also ask a variety of text-based questions to this Another Me.
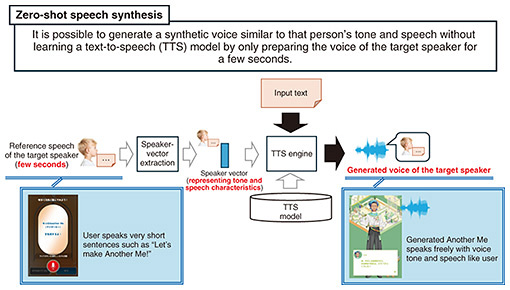
We are adding the necessary elements to Another Me so that users can feel like it is more like themselves. We take advantage of the surface layer to make the voice that Another Me speaks more like the user’s, i.e., not simply focusing on appearance. The content that Another Me talks about is determined on the basis of the characteristics of the user. We are using the following technologies under research and development at NTT laboratories to achieve this. 4. Technologies that make up Another Me in Another Me Planet4.1 Zero-shot text-to-speech synthesis technologyIn Another Me Planet, users record a few seconds of their voice then listen to messages from their “future self” in a career of their choice, with the voice reflecting the user’s unique vocal characteristics. This audio is generated using one of the latest features of NTT laboratories’ text-to-speech synthesis technology [3]: zero-shot speech synthesis (see Fig. 5).
Zero-shot speech synthesis enables the generation of synthetic speech closely resembling the voice one wants to synthesize (target speaker’s) by simply preparing a few seconds of reference speech from the target speaker. This technology accurately extracts the characteristics of the reference speech and reflects them in the synthetic speech without requiring any additional training of the speech-synthesis model for the specific speaker. Thus, the burden on users and service providers is limited to preparing just a few seconds of reference speech, making the technology highly accessible. It will be useful for a wide range of target speakers and user groups including extremely busy public figures and corporate executives and the elderly or young children who may find it difficult to record long samples. By extracting reference speech from previously recorded data, this technology can be used in various scenarios such as recreating the voice of someone who has lost their ability to speak or generating audio using a person’s voice before it changed (e.g., before puberty). 4.2 Speech generation and ethical-inappropriateness-estimation technique using NTT’s large language model “tsuzumi”In Another Me Planet, users can interact with an Another Me who has a future occupation. The engine that generates utterances of this Another Me in Japanese uses tsuzumi [4], a large language model that NTT is developing. On the basis of the future occupation of Another Me determined by the user and the personality and work characteristics of Another Me set on the basis of the answers to the questionnaire, a prompt is created to automatically generate utterances of this Another Me to resemble the user (Fig. 6).
For the candidate utterances of Another Me generated with tsuzumi, a technology [5] under research and development at NTT laboratories is also used to further improve the quality of the final utterance content. It automatically determines the level of ethical inappropriateness of the generated utterances, confirms that the likelihood of problematic words and sentences being included is low enough, then determines the final utterance of Another Me. When a sentence to be judged is input, it is possible to respond with the degree of ethical inappropriateness of the input sentence and the reasoning. 5. Future prospectsWith the remarkable technological progress of artificial intelligence (AI), it is becoming more closely involved in many aspects of our lives. Through Another Me Planet, we will continue to collect information obtained through the construction of Another Me Planet application, as well as impressions and system-usage data obtained through social networking services throughout the session, to explore better relationships between humans and AI that directly interacts with humans, including Another Me Planet. We plan to deepen our knowledge of the acceptability of communication by such AI from various user perspectives and the effectiveness of various technologies including speech generation. References
|
|||||||||||