|
|||
|
|
|||
       |
Feature Articles: NTT R&D at Expo 2025 Osaka, Kansai, Japan Vol. 23, No. 10, pp. 45–50, Oct. 2025. https://doi.org/10.53829/ntr202510fa5 A Pavilion Clad in Emotions: Harmonized Communication Experiences between People and ObjectsAbstractThis article introduces one of the key concepts behind the NTT Pavilion at Expo 2025 Osaka, Kansai, Japan: the creation of future communication through the Pavilion Clad in Emotions. It showcases the efforts behind IOWN (Innovative Optical and Wireless Network) Photonic Disaggregated Computing and MediaGnosis, NTT’s next-generation media processing artificial intelligence. It also presents initiatives using IOWN Photonic Disaggregated Computing and Embodied Knowledge Understanding Technology to ensure safety and security for visitors to the NTT Pavilion. Keywords: IOWN Photonic Disaggregated Computing, data-centric infrastructure (DCI), photonics-electronics convergence (PEC) devices
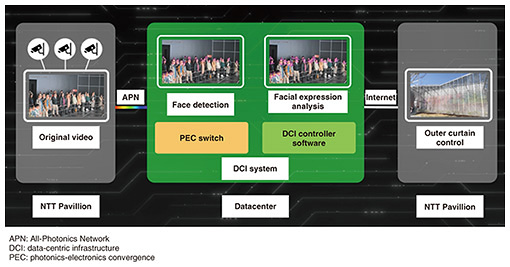
1. Production overview of the NTT Pavilion at Expo 2025 Osaka, Kansai, JapanTo create future communication in which human emotions and sensations are linked with objects, NTT used Innovative Optical and Wireless Network (IOWN) Photonic Disaggregated Computing, the computing platform of the IOWN era, along with its proprietary next-generation media processing artificial intelligence (AI) MediaGnosis. In Zone 2 of the NTT Pavilion, where performances by the music group Perfume were presented, five cameras were installed to capture visitors’ facial expressions. These images were analyzed once per second to count the number of smiles. On the basis of the number of smiles detected, the curtain that enveloped the pavilion was dynamically and intricately controlled (Fig. 1).
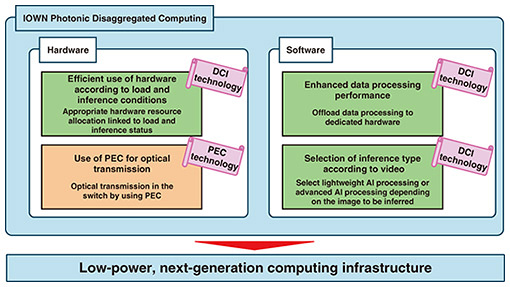
To provide a safe and secure experience for visitors, NTT implemented a system that combines IOWN Photonic Disaggregated Computing with Embodied Knowledge Understanding Technology. Sixteen cameras installed around the pavilion detected individuals and calculated crowd density by dividing the number of people detected by the area covered by each camera. The system also estimated skeletal posture to determine whether a person has fallen. If a fall was detected, the location information was sent to mobile devices used by pavilion staff. Upon receiving the alert, staff could promptly guide visitors to alleviate congestion or assist those who have fallen, enabling swift and responsive operations. 2. Features of IOWN Photonic Disaggregated ComputingIOWN Photonic Disaggregated Computing is a next-generation computing platform composed of a hardware layer consisting of servers equipped with graphics processing units (GPUs) and photonics-electronics convergence (PEC) switches and a software layer featuring the data-centric infrastructure (DCI) controller, which flexibly manages GPU and other accelerator resources (Fig. 2).
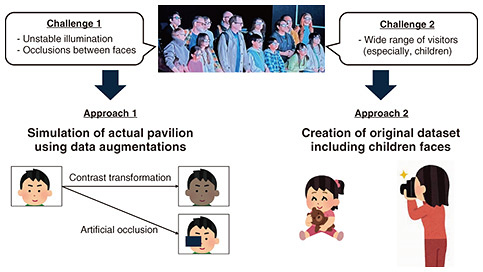
The use of AI for video processing has been accelerating in fields such as marketing and security. However, conventional systems face challenges such as the linear increase in physical resource usage, such as GPUs, and the limitations of Ethernet-switch processing capacity due to growing data traffic. In particular, the increase in power consumption has raised concerns about its environmental impact. To address these issues, IOWN Photonic Disaggregated Computing promotes efficient use of physical resources and applies PEC devices to Ethernet switches, thus reducing power consumption to one-eighth compared with standard server configurations. The DCI controller has three main features. The first feature is a software implementation technique that draws out the full potential of cutting-edge hardware to achieve high-performance data processing. By offloading processing to dedicated hardware, such as GPUs and SmartNICs (smart network interface cards), it enables fast data processing and low power consumption. The second feature is a technology that optimizes hardware usage according to the load and inference conditions of the applications. For example, in the case of video analysis of people, the system increases the number of physical resources, such as GPUs, during busy daytime hours and reduces them during quieter nighttime periods. Adjusting the amount of physical resources required for inference contributes to reducing power consumption. The third feature is inference selection technology tailored to the content of the video. Unlike conventional methods that apply the same inference regardless of whether people appear in the image, this technology distinguishes between images with and without people. Images with people are processed using advanced inference, while those without are handled with lightweight inference. By determining the type of inference for each image, the system minimizes the number of advanced inference executions and achieves lower power consumption. The PEC switch differs from conventional Ethernet switch mechanisms in that it replaces internal electrical connections with optical ones. By incorporating PEC devices, the PEC switch supports 128 Ethernet ports within a single compact chassis, thus improving performance and reducing power consumption. The PEC devices embedded within the PEC switch are extremely compact and efficient components. They offer data processing performance equivalent to eight conventional 400G optical modules while consuming only half the power. 3. Features of MediaGnosisIn the NTT Pavilion, we analyzed the facial expressions of visitors and controlled the facade accordingly. Specifically, the faces detected with the DCI technology were analyzed by MediaGnosis, which is NTT’s original AI. From the analysis results, we calculated the ratio of happy and surprised visitors and reflected it into the control of the facade as the excited state. Toward Expo 2025 Osaka, Kansai, Japan (hereafter referred to as Expo 2025), we improved the facial expression analysis engine in MediaGnosis to resolve the following two issues (Fig. 3).
The first issue is that in Zone 2 of the NTT Pavilion, where five cameras capture visitors, the illumination conditions are highly unstable due to the performance-driven displays as well as light-emitting diodes installed on the stage that frequently turn on and off. Consequently, the appearance of visitors’ faces changes significantly over time. Additionally, when multiple visitors appear in the same camera frame, some faces often overlap and cannot be fully captured. Facial expression analysis requires detailed facial information; however, it must work robustly even under these challenging conditions. To address this challenge, we incorporated more than ten data augmentation techniques during the training of the AI model, including contrast transformations and artificial image occlusions. These augmentations simulate variations that may occur in our actual pavilion. By doing so, the AI model can perform consistently even under such unstable conditions. We thus successfully developed a facial expression analysis AI system with high robustness, even in the complex and unstable conditions expected at Expo 2025. The second issue is a wide range of age groups were expected to visit our pavilion. Especially, a large number of children were anticipated. However, most publicly available datasets for facial expression analysis consist primarily of facial images of individuals over age 15. This poses a significant challenge for achieving high-performance facial expression analysis for individuals under the age of 15. One possible reason is that publicly accessible datasets often exclude children’s facial images due to concerns about privacy. Therefore, it remains difficult to improve the AI’s accuracy in analyzing children’s facial expressions using many public datasets. To address this, we created a valuable original dataset consisting primarily of facial images of individuals aged 0 to 15, which is accessible only within NTT laboratories. Since it is difficult to capture a number of child participants comparable with that of adult datasets, we prepared a wide variety of camera angles and background patterns during data collection to maximize variation, even with a limited number of subjects. By leveraging this dataset for training, we successfully enhanced the facial expression analysis performance across a broad range of age groups, including children. Before Expo 2025’s opening, we conducted a field trial of the improved facial expression analysis AI model in Zone 2 of the actual NTT Pavilion. Through this trial with extras representing a wide range of ages and nationalities, we were able to confirm that the model delivers sufficient performance and robustness under dynamic stage conditions. We believe that this achievement demonstrates the strength of MediaGnosis. Its applications extend beyond Expo 2025 to a wide range of potential use cases. 4. Features of Embodied Knowledge Understanding TechnologyEmbodied Knowledge Understanding Technology is a technology that recognizes human behavior from surveillance cameras and cameras mounted on robots. At Expo 2025, the NTT Pavilion used video footage from cameras installed outside the pavilion to detect individuals who have fallen within the premises using AI on the DCI system, thus efficiently achieving surveillance of the NTT Pavilion through the DCI system. Many fall detection technologies either deploy AI models directly on edge devices, such as surveillance cameras, or install AI models on central processing unit (CPU)/GPU servers. However, the former approach often requires simplifying the AI models, which can result in reduced accuracy, while the latter does not efficiently process for multiple people across numerous cameras. To enable efficient AI-based monitoring for the 16 cameras installed around the NTT Pavilion, it was necessary to develop a fall detection system with an AI model capable of multi-camera, multi-person inference. There are two key technical points (Fig. 4). The first is the construction of a fall detection model that can adapt to variations in camera height and angle. The cameras installed outside the NTT Pavilion were positioned at various heights, ranging from approximately 4 to 8 meters, and their angles also differed significantly. Previous fall detection models were mainly designed for indoor environments, which made it difficult for them to adapt to the diverse heights and angles of outdoor cameras. To address this challenge, we created a video dataset modeled after an event venue to develop a fall detection model that can adjust to changes in camera height and angle. This dataset includes multi-camera, multi-person video footage by simulating a scenario in which approximately 50 performers are present at an event venue, engaging in various actions including falls, all of which were then annotated. Using this dataset, we constructed a model capable of detecting falls in video footage from cameras with a wide range of heights and angles, achieving better performance than with conventional fall detection models.
The second key point is a person tracking technology that is independent of the number of people present. To detect falls, it is first necessary to detect individuals, then monitor whether they remain stationary for a certain period, and finally issue a fall alert if the relevant criteria are met. It is thus essential to track every person appearing in the video, assign them an identifier, and manage their status accordingly. Tracking each individual traditionally requires dedicated processing resources for each person, resulting in increased computational load as the number of people grows. This limitation has made it difficult to apply the technology to large-scale event venues, where cameras often capture many people simultaneously. With our technology, we constructed a robust person tracking model that is resilient to fluctuations in the number of people by enabling parallel processing of internal tracking operations for each individual on a GPU. Specifically, by offloading loop processing—which previously had to be executed on a CPU—to parallel processing on a GPU, we minimized the increase in CPU load even when multiple people appear across multiple camera feeds, enabling efficient GPU execution. 5. Future outlookDCI will continue to develop by leveraging the insights gained through its implementation at Expo 2025, with the goal of completing a commercial version by fiscal year 2026. To actualize the IOWN vision for 2030, efforts will be made to further reduce power consumption and generate new value. PEC devices will undergo further miniaturization and be adapted to replace electrical connections within computers, including those between CPUs and GPUs, with optical connections. A resource pooling mechanism will be introduced to aggregate resources of the same type, such as CPUs and GPUs, enabling the creation of computers that can freely connect to the necessary physical resources. These developments will contribute to even greater reductions in power consumption. MediaGnosis is a media processing AI with a wide range of capabilities, not limited to facial expression analysis. One can also experience it through its demo site (https://www.rd.ntt/mediagnosis/demo/). On the basis of the technologies and data accumulated through our efforts at Expo 2025, we believe that we can further enhance the robustness of MediaGnosis, even under unstable conditions. Embodied Knowledge Understanding Technology will enable the development of technology for efficiently recognizing behavior from multiple cameras and multiple people, obtained at Expo 2025, and we aim to establish technology that can detect not only falls but also more advanced human behavior in real time in a multi-camera, multi-person environment. This will enable us to expand the application of this technology to work behavior in a variety of industries. |
||