|
|||||||||||||||||||||
|
|
|||||||||||||||||||||
|
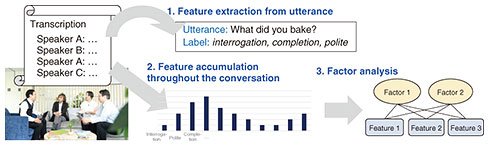
Feature Articles: Exploring Humans and Information through the Harmony of Knowledge and Envisioning the Future Vol. 23, No. 10, pp. 61–66, Oct. 2025. https://doi.org/10.53829/ntr202510fa8 Techniques for “Reading the Room” in Attentive Conversational AI—Understanding Dialogue Context through Multimodal Information and Incremental Response GenerationAbstractTo enable dialogue systems to blend seamlessly into people’s daily lives and engage in thoughtful behavior, it is essential for them to possess the ability to “read the room”—that is, to recognize the dialogue situation and relationship between interlocutors and respond with appropriate timing. With this goal in mind, our group has been conducting research on a variety of dialogue processing technologies aimed at developing such situation-aware dialogue systems. This article highlights three of our studies: dialogue situation recognition for understanding everyday conversations, intimacy recognition for estimating interpersonal closeness between speakers, and incremental response generation for adapting to the natural tempo of human interaction. Keywords: dialogue situation recognition, interpersonal closeness recognition, incremental response generation  1. Dialogue processing for “reading the room”Advances in large language models have dramatically improved the naturalness of responses in dialogue systems. Conversational interaction with artificial intelligence (AI) applications, such as ChatGPT, has become commonplace. However, for dialogue systems to truly be integrated into our daily lives and exhibit thoughtful behavior, they must also learn to “read the room.” For instance, to enliven casual conversations among friends or offer appropriate advice during tense discussions, such a system must be able to accurately interpret the dialogue situation, including the relationships among participants and the purpose of the conversation. In some cases, such as mediating conflicts, it may even be necessary for the system to consider the psychological distance between individuals. The ability to respond at the right moment, in sync with the natural tempo of conversation, is also essential. To develop dialogue systems that can coexist with humans as partners, our group has been conducting research on various dialogue processing technologies that enable systems to read the room. This article introduces three of these studies. 2. Dialogue situation recognitionFor dialogue systems to naturally participate in everyday conversations, they must exhibit behavior appropriate to the situations. For example, the type of interaction expected from a system differs depending on whether it is involved in a casual chat between friends at a café or a discussion between colleagues at the office. In the former, we would expect the system to speak in a casual tone and help energize the conversation, whereas in the latter, it should adopt a more formal tone, avoid interrupting, and carefully time its contributions. In this study, we aimed to develop such situation-aware dialogue control. We first investigated the linguistic characteristics of conversations across different situations using factor analysis [1]. Figure 1 illustrates an overview of the factor analysis procedure. From each utterance, we extracted elements such as the speaker’s intent, psychological stance, and grammatical features. These elements were aggregated across each dialogue and represented as feature vectors. Applying factor analysis to these vectors enabled us to identify latent dimensions (i.e., factors) that explain key characteristics of conversations. Using the Corpus of Everyday Japanese Conversation provided by the National Institute for Japanese Language and Linguistics [2], we extracted seven such factors. Drawing on insights from conversation analysis in linguistics and sociology, we labeled these factors explanation, request, narrative, politeness, affective, involvement, and suggestion. These can be interpreted as elements related to the style and communicative purpose of the dialogue. A comparison of the factor weights across different conversational situations revealed meaningful differences. For example, conversations in meetings were characterized by a strong explanatory component; those between colleagues emphasized politeness; and conversations among friends were rich in emotional expression. These insights are expected to inform the design of dialogue strategies for dialogue systems integrated into daily life.
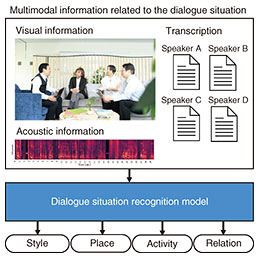
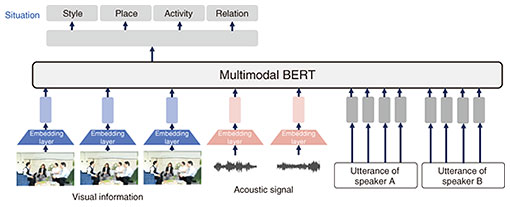
Next, we developed a model to automatically estimate the dialogue situation on the basis of contextual information surrounding the conversation (dialogue situation recognition model). This model leverages visual, acoustic, and linguistic information from recorded dialogue scenes to estimate four aspects of the dialogue situation: dialogue style, place, activity accompanying the conversation, and relationship between participants (Fig. 2). As the backbone of our model, we adopted BERT (Bidirectional Encoder Representations from Transformers), which was widely used at the time for classification tasks in the field of natural language processing. Figure 3 illustrates our model. Visual and acoustic information are transformed into embedding vectors using pre-trained models and combined with language embeddings as input to the model. Notably, certain correlations are known to exist among the four dialogue aspects. For example, conversations with family members often occur at home, while those with professional contacts are more likely to take place in offices or schools. To capture these interdependencies, we treated each aspect as a separate prediction task and introduced a multi-task learning framework to model the relationships among tasks. Experimental results indicate that integrating visual, acoustic, and linguistic information led to improved performance, and that incorporating multi-task learning further enhanced the accuracy of situation recognition [3].
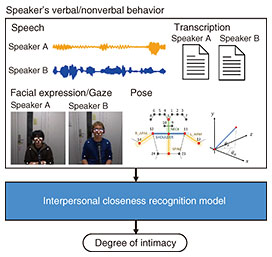
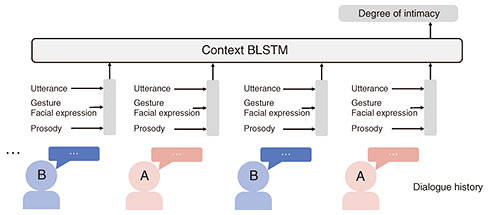
3. Recognition of interpersonal closeness between speakersHuman behavior varies depending on the degree of intimacy felt toward others. For example, politeness theory [4] argues that a speaker’s linguistic behavior is influenced by interpersonal closeness and hierarchical relationships, while social penetration theory [5] posits that the depth of self-disclosure changes with the level of intimacy. In terms of nonverbal behavior, it has been suggested that individuals tend to exhibit synchrony, such as mimicking gestures or postures, when interacting with someone they feel close to [6]. These insights suggest that a system’s ability to understand a speaker’s sense of intimacy is crucial for building social relationships with humans. We investigated a method for estimating the speaker’s interpersonal closeness (i.e., sense of intimacy) toward their conversational partner on the basis of both verbal and nonverbal behaviors. We used the SMOC (Spontaneous Multimodal One-on-one Chat-talk) corpus, which contains recordings of casual conversations between university and graduate students, and analyzed verbal and nonverbal behaviors indicative of interpersonal closeness. For verbal behavior, we extracted the speaker’s intent as well as psychological and social elements expressed in the utterances. For nonverbal behavior, we analyzed prosodic features (e.g., speech rate, pitch, and response timing), facial expressions, gaze, and posture. The analysis of verbal behavior revealed that conversations between speakers with high intimacy contained more utterances expressing negative emotions, while those between speakers with low intimacy included more frequent questions about the partner’s desires and habits. These findings suggest that closer relationships encourage more direct emotional expression, whereas early-stage relationships tend to involve more exploratory dialogue aimed at learning about the other person. The analysis of nonverbal behavior showed that facial expressions, postures, and certain gestures were more synchronized between speakers with high intimacy. The results indicate that the extracted verbal and nonverbal features are effective for estimating interpersonal intimacy. On the basis of these findings, we constructed a model to estimate the degree of intimacy between speakers using the extracted features (interpersonal closeness recognition model) [7] (Fig. 4). Figure 5 illustrates this model. First, linguistic, prosodic, facial, and postural information is extracted from each utterance and integrated using a multi-stream bi-directional long short-term memory (MS-BLSTM) network. This output is then passed to a contextual BLSTM to estimate the level of intimacy in three stages. Experimental results indicate that this model outperformed several baseline models. In particular, it achieved higher accuracy than previous models that rely only on textual information, demonstrating that multimodal features are effective in estimating the interpersonal closeness between speakers.
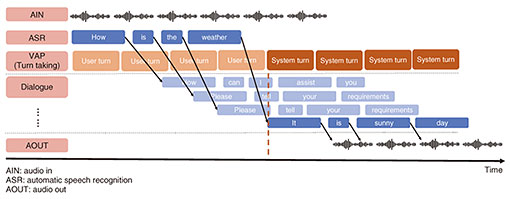
4. Incremental response generation aligned with human conversational timingIn human conversation, not only the content but also turn-taking is crucial. People are believed to engage in conversation while continuously predicting both what they will say next and when to speak on the basis of their interlocutor’s utterances. This enables rapid speaker transitions with minimal delay. In contrast, the response generation process in dialogue systems is quite different. In typical pipeline-based spoken dialogue systems, the modules for speech recognition, response generation, and speech synthesis operate in a synchronous manner. In other words, each module begins processing only after the previous one has finished. Therefore, the time required for speaker transitions is generally longer than in human conversation. We aimed to shorten the dialogue system’s response time by implementing a response generation mechanism inspired by the human strategy of planning the next utterance while listening to the interlocutor. Figure 6 illustrates an overview of the incremental response generation method we developed. User utterances are recognized incrementally through streaming speech recognition, and the system begins generating responses each time a partial recognition result is received. This enables the system to prepare multiple candidate responses even before the user has finished speaking. At the appropriate turn-taking moment, the system selects the most suitable candidate and presents it as the final response. This response generation mechanism has been integrated into a dialogue system development toolkit jointly developed with Nagoya University [8], and has been made publicly available for broader use. For turn-taking prediction, we adopted voice activity projection (VAP), one of the state-of-the-art methods in this field.
Using our incremental response generation method, we investigated the impact of incremental response generation on dialogue performance, including user evaluations and task success rates [9]. We used common dialogue system evaluation metrics such as user satisfaction, coherence, and naturalness, as well as metrics specific to speech interfaces [10]. For task-oriented dialogue, we also evaluated the task success rate. The results indicate that although our incremental response generation method successfully reduced response time, user evaluations were lower compared with those with conventional methods. One key reason is that shorter response times limit the amount of user utterance available for response generation, increasing the likelihood of incoherent or inappropriate responses. These findings suggest that achieving more satisfying conversations requires not only advanced turn-taking prediction but also accurate response generation aligned with that timing. Humans are believed to maintain coherent conversations by considering the characteristics of their interlocutors, referencing prior dialogue context, and predicting what their partners might say next. Similarly, incremental response generation should incorporate such contextual and predictive information to ensure fluent interaction. 5. Conclusion and future perspectivesThis article introduced three studies from our group that focus on dialogue processing technologies aimed at equipping dialogue systems with the ability to read the room. For dialogue systems to participate naturally in human conversation and serve as partners that coexist with people, further improvements in the accuracy of each technology are essential. At the same time, it is important to broaden the scope to include a wider range of dialogue-processing capabilities. For example, most dialogue systems are designed for one-on-one interactions, and managing multi-party conversations remains a significant challenge. Developing robust systems that can engage in dialogue with diverse users, such as older adults and children, is also crucial. To carry out tasks flexibly in response to changing situations during interaction and appropriately respond to misunderstandings in communication, research on dialogue strategies is also indispensable. We will continue to advance our research on these various aspects of dialogue processing technologies.
Some of the work introduced in this article was conducted in collaboration with Nagoya University and Tohoku University. References
|
|||||||||||||||||||||