|
|||||||||||||||||||||||
|
|
|||||||||||||||||||||||
       |
Feature Articles: Exploring Humans and Information through the Harmony of Knowledge and Envisioning the Future Vol. 23, No. 10, pp. 67–72, Oct. 2025. https://doi.org/10.53829/ntr202510fa9 AI that Learns to Listen on Its Own—Advancing Self-supervised Audio Representation toward Cutting-edge Sound Understanding with Large Language ModelsAbstractRepresentation learning―which enables the extraction of meaningful features from media such as audio and images―has greatly advanced artificial intelligence (AI)’s ability to understand media content. This article introduces technologies that we developed for learning audio representations that allow AI to comprehend the diverse sounds that surround us. The learned representations can be applied to a wide range of sound applications, such as identifying animal vocalizations or music genres. We focus on self-supervised learning, a form of representation learning that uses only audio data to avoid the labor cost of annotating data, to further develop our technologies. We also extend these technologies by aligning audio understanding with the language semantics, leveraging large language models. Keywords: representation learning, self-supervised learning, sound understanding
1. IntroductionRepresentation learning*1, which enables the automatic extraction of useful features from media content such as audio and images through training, has significantly enhanced artificial intelligence (AI)’s ability to understand such data. This article introduces technologies that we developed for learning audio representations that enable AI to comprehend the various sounds around us. Deep learning*2 models trained through this approach can be applied to a wide range of audio understanding tasks, such as recognizing sounds like human voices and animal vocalizations, or identifying music genres. Among the various representation learning paradigms, self-supervised learning*3 has gained attention as an alternative to conventional supervised learning*4 methods, which require labeled data that indicates the content of each audio clip. Self-supervised learning instead generates training labels automatically from the data itself. This makes it possible to leverage large-scale unlabeled data to learn more robust and effective audio representations. We have been advancing our technologies by employing this self-supervised approach, and our methods have further evolved to align audio with language representations, reflecting the increasing need to handle media content via natural language. We also extended these methods to utilize large language models (LLMs), taking advantage of their powerful semantic understanding of text.
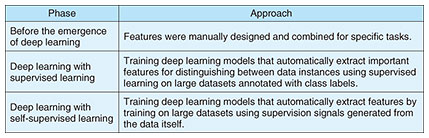
2. Representation learning: Foundational technology for understanding media contentRepresentation learning is a fundamental technology that enables computers to understand media content—such as audio and images—by learning to automatically extract useful features, or representations*5. In the past, features such as loudness, pitch, or frequency components were manually designed using signal processing techniques to suit specific applications. However, this manual approach reaches its limits when it comes to understanding diverse and complex sounds, such as conversational speech, vehicle noises, or animal calls. To address this challenge, deep learning emerged as a solution. Deep learning enables representation learning that can automatically extract the most relevant features for distinguishing between different types of audio, leading to more advanced understanding. In its early stages, deep learning relied on supervised learning approaches that use labeled data. More recently, self-supervised learning has gained attention for its ability to learn representations without the need for labeled data by discovering rich patterns inherent in large-scale datasets. This approach eliminates the high cost of manual labeling by generating supervision signals directly from the data itself, making the training process more efficient (see Table 1).
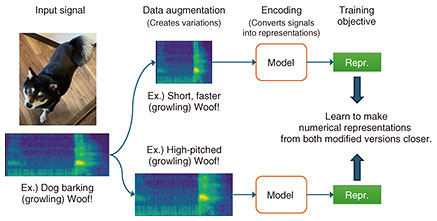
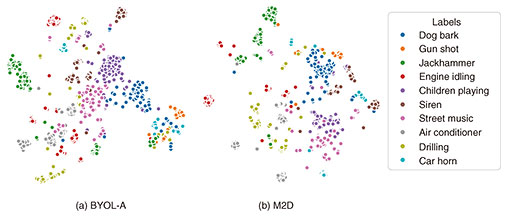
3. BYOL for audio: Learning representations robust to subtle differences in soundAs a first step toward learning effective features for diverse audio, we proposed BYOL for Audio (BYOL-A) [1], a self-supervised learning method based on the image-based technique Bootstrap Your Own Latent (BYOL). BYOL-A learns numerical representations that capture underlying sound patterns while suppressing minor differences. For example, a dog’s bark may vary depending on pitch, loudness, or breed, yet it is generally understood simply as a “bark.” BYOL-A is designed to learn to extract the same representation for such variations when they belong to the same sound pattern, thereby enabling more useful audio representations (Fig. 1). To achieve this, BYOL-A learns representations that are robust to small changes in the audio. Specifically, the model is trained using two versions of the same sound, each modified with random changes in characteristics such as background noise, duration, pitch, and volume. It is then optimized so that the numerical representations from both modified versions match as closely as possible. Therefore, BYOL-A is designed to encourage models to automatically extract meaningful representations that capture the essential characteristics of the sound by training them to produce the same representation even when the original sound is altered in different ways. As a result, this method significantly improved the performance of audio-related tasks—for example, achieving over a 20-percentage-point gain in spoken keyword spotting. This performance gain can be attributed to the learned representations naturally forming clusters of similar sounds across various tasks, making classification much easier (Fig. 2(a)).
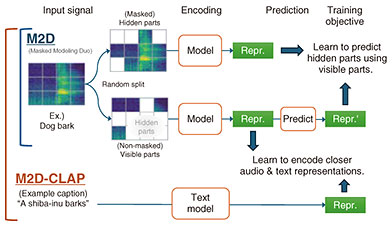
The key to this technique lies in its learning mechanism. The immediate objective is to train the model to produce similar representations for two sounds that differ slightly in their characteristics. But as a byproduct, the learned representations begin to reflect the semantic meaning of the sounds, forming natural clusters based on sound types. This seemingly indirect approach allows the AI to learn “how to listen”—a process like the saying “When the wind blows, the cooper profits.” That is, through what may seem like an indirect mechanism, the model ultimately gains the ability to understand audio in a meaningful way. Here, “semantic meaning of sound” refers to task-dependent sound concepts—for example, whether a sound is a dog’s bark or a musical instrument. The representations learned through this process reflect the inherent characteristics of sounds, enabling the model to form distinct clusters based on the relevant sound concepts for each task. This kind of algorithmic ingenuity is what makes self-supervised learning research so fascinating. 4. Masked Modeling Duo: Learning rich representations through fill-in-the-blank taskIn BYOL-A, learning is driven by introducing variations to the audio input. However, this approach faces limitations in capturing the detailed characteristics of the altered portions of the sound. To address this, we proposed a new self-supervised learning method called Masked Modeling Duo (M2D) [2], which aims to extract features that reflect the essential structure of sound—including subtle variations—by learning through a masked audio prediction in which the model predicts hidden segments of an audio signal (Fig. 3, top). Learning methods that involve predicting masked or future parts of input data have shown great success in natural language processing—most notably in LLMs—and are known to enable the learning of high-quality representations. In M2D, visible parts of the input audio are first encoded into representations, and then these representations are used to predict the representations of the masked parts. For example, when predicting missing segments from a piece of music, the model must learn features that capture musical structure and rhythm. Similarly, when training on various audio types—such as dog barks, musical performances, or ocean waves—M2D learns to extract features that imply the underlying structural patterns of each sound.
Unlike BYOL-A, this learning approach enables representations to distinguish fine-grained differences. For instance, accurately predicting a masked portion of a piano performance requires the model to retain precise information such as pitch, note duration, and intensity in the representation. Because the model is optimized to improve prediction accuracy, the resulting representations naturally capture such detailed audio characteristics. As a result, M2D forms more tightly clustered groups of audio representations by sound type (Fig. 2(b)), and consequently achieves significantly improved performance in many downstream tasks. For example, in heart sound classification using auscultation recordings, M2D outperformed BYOL-A—which had fallen short of conventional methods—in detecting heart murmurs that may indicate signs of disease [3]. This improvement is attributed to M2D’s enhanced ability to retain information about subtle noise components in heart sounds, which are critical for such medical diagnostics. 5. M2D-CLAP: Aligning audio with natural language descriptionsIn recent advances in generative AI, interaction via language has become essential. As a result, techniques that align media content with language have emerged as key components for enabling AI to understand and generate information. In this context, we proposed M2D-CLAP [4], a method that not only learns numerical representations of audio but also aligns them with corresponding natural language descriptions. To achieve this, M2D-CLAP integrates M2D, which learns through fill-in-the-blank task on audio signals, with Contrastive Language-Audio Pre-training (CLAP), which learns the alignment between audio and language. This approach enables the model to align audio signals with their captions by making the similarity between their representations higher (Fig. 3, bottom). For example, a sound caption “thunderstorm” and its actual audio waveform are mapped to similar numerical representations, while sounds of a different nature are mapped to distinct representations. This allows for applications such as retrieving audio using text queries like “dog barking,” or performing zero-shot classification for newly defined labels (e.g., “electric vehicle” or “motorbike”) without requiring them to be seen during training. While this enables solving audio-related problems through language, incorporating CLAP, which is based on supervised learning, introduces the cost of preparing corresponding captions for training. However, with recent advances in technologies that automatically describe audio content, such as acoustic event detection, there is a growing trend toward leveraging automatically generated audio captions for training audio representations. M2D-CLAP embraces this trend by using such automatically generated captions for training. In addition to learning audio-language aligned representations through CLAP, M2D-CLAP also achieves state-of-the-art performance in conventional audio representation learning tasks, differentiating it from other methods. In this way, M2D-CLAP provides versatile and general-purpose representations that can be widely applied across a variety of tasks involving both audio and language. 6. M2D2: Learning from the knowledge of large language modelsM2D2 [5] is a framework that incorporates the knowledge and deep semantic understanding of LLMs into audio representation learning. For example, when prompted with a question like “What sounds do various metals make when struck?”, an LLM provides a detailed explanation of the expected acoustic characteristics of different metals, grounded in knowledge of their physical properties. This demonstrates that LLMs possess extensive knowledge about sound-related phenomena. Moreover, LLMs exhibit a deep understanding of subtle differences in textual phrasing and nuance, as evidenced by their conversational responses. By using an LLM as the text encoder model within the M2D-CLAP framework, M2D2 enables the model to learn audio representations that are aligned with language representations enriched by the LLM’s knowledge. In this way, audio representations are learned through the lens of language representations that reflect the LLM’s understanding of the world. As a result, M2D2 achieves a more sophisticated understanding of sounds and improves performance in tasks such as audio-based retrieval and automatic audio captioning. Furthermore, the representations learned from LLMs can be combined with the LLM itself to enable even more advanced applications, such as interactive dialogue grounded in audio-based situational understanding, going beyond simple audio captioning. 7. ConclusionThrough the progression of these technologies, audio representations have evolved beyond merely capturing acoustic characteristics—they are now becoming general-purpose representations that can be linked with linguistic meaning and enriched by the knowledge embedded in LLMs. However, these technologies are still in the research stage, and many challenges remain before practical deployment. For example, compared to images or text, audio data is significantly scarcer, posing limitations on training and evaluation. Looking ahead, our goal is to overcome these challenges and enable AI systems that can learn from and understand the sounds present in our everyday lives. This could open the door to a wide range of sound applications, such as services that monitor daily health conditions through audio, contributing to practical solutions across various domains. References
|
||||||||||||||||||||||