|
|||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||
       |
Feature Articles: AI Constellation—Toward a World in Which People and AI Work Together Vol. 23, No. 11, pp. 27–33, Nov. 2025. https://doi.org/10.53829/ntr202511fa2 Research and Development toward AI ConstellationAbstractDiscussions held within a multi-agent system, such as AI Constellation, are expected to solve problems on the basis of diverse viewpoints by using multiple large language models (LLMs). However, simply combining language models results in generating similar and abstract responses, and the lack of deep discussions has become an issue. This article introduces LLM-agent response-diversifying technology for automatically selecting new viewpoints while maintaining discussion flow. Keywords: AI Constellation, large language model, next-generation AI
1. Complex social issues and expectations of AI discussion technologyImproved performance in large language models (LLMs)*1 has been accompanied by growing interest in a multi-agent system (MAS)*2 for discussion in which multiple artificial intelligence (AI) models participate in discussions, each with a different point of view [1, 2]. These technologies, when faced with problems that traditionally require deliberation among experts and have no clear answers, may not only be capable of presenting issues or solutions that humans on their own may overlook but also hold the possibility of finding hard-to-notice assumptions and latent needs. By providing a discussion environment unrestricted by time and place, they can be used in situations where it is difficult to obtain diverse viewpoints due to the small number of participants or bring stakeholders together in one place. For example, a workshop attended by a number of people to address a regional issue such as nursing care or disaster prevention takes on a complex problem, the desired solution of which differs according to one’s position. These technologies hold great promise as a means of stimulating discussion by providing new perspectives on expertise that previously required fieldwork to acquire. There will be increasing demand for AI discussion technology at such participatory workshops not only to exchange diverse opinions in a natural manner much like discussions among people but also to bring about new insights among participants for problems having no clear solution. This article introduces LLM-agent response-diversifying technology for automatically selecting new viewpoints while maintaining discussion flow and describes associated issues, detailed configuration and evaluation, and future developments.
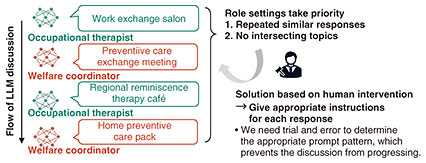
2. Technical issues: Limits in naturalness and diversity of MAS discussionsIn a MAS, discussions are held from diverse viewpoints by giving LLM agents different roles and areas of expertise. However, simply combining multiple LLM agents causes the two technical issues shown in Fig. 1 and detailed as follows.
The first issue is that it is difficult for each agent to correct or evolve its opinion throughout discussion. An LLM agent tends to strictly adhere to the given topic and instructions on role and expertise. Once it provides an opinion, it will not change it according to the flow of discussion or responses of others. The result is that each agent expresses similar opinions even after repeated discussions, and a breadth of viewpoints and ideas expected from the MAS cannot be sufficiently achieved. It is particularly important to generate diverse responses that are not simply repetitive or similar to create new value through discussion. The second issue is that points of discussion often do not intersect even if the discussion progresses. Although an LLM can reference the responses of other agents, each agent tends to follow the given instructions only and ignore the opinions of others when generating its response. Responses thus tend to be independent, which prevents the discussion from meshing and makes interactions between agents with opposing views difficult. In particular, agents lack communications such as rebutting the responses of others or deepening the discussion based on empathy, which would naturally occur in human discussions. In short, there is a tendency for discussions to end without reaching a conclusion. These two issues naturally arise from the characteristics of LLMs; thus, they can significantly reduce the value of experiencing a discussion in a participatory workshop. It had been necessary to manually adjust a prompt*3 according to the state of the discussion and instruct an appropriate attitude or viewpoint for each response. This was done to facilitate a concrete discussion while suppressing similar responses and maintaining diverse responses. However, we need to try a number of prompt patterns in a trial-and-error manner. This not only increased the operating burden but also hindered the progress of the workshop; therefore, this approach was not realistic. To cope with such a problem, we need automatic control technology that can achieve diverse responses and a natural discussion simultaneously.
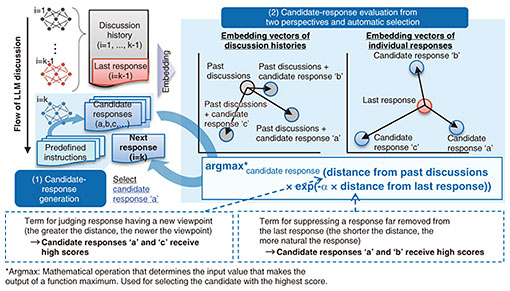
3. LLM-agent response-diversifying technology3.1 Aim of the technology and basic policiesAs described above, conversations between LLMs in a conventional MAS strongly tend to follow previously given instructions as to topic, roles, etc. This causes no intersecting point of discussion and similar content even as the discussion progresses. We thus need human intervention at appropriate times to adjust the direction of the discussion. To address this issue, LLM-agent response-diversifying technology gives importance not only to the responses from new viewpoints but also to those which naturally evolve along with the discussion flow. This is because simply pursuing a response from a new viewpoint may diverge from the original topic, which makes the discussion difficult to understand. Ensuring both diversity and naturalness of the responses in a discussion, that is, generating balanced opinions that are neither deviating from the original point of discussion nor too conservative, is the key to this technology. This technology is designed on the basis of the following two policies, as shown in Fig. 2:
On the basis of the above process, we aim to generate natural, concrete, and diverse dialogue without human intervention. 3.2 Candidate-response generation: Using diverse instruction templatesTo maintain diversity in responses, it is important to have an LLM agent think from a different angle in respect to the same topic. LLM-agent response-diversifying technology prepares multiple instruction templates beforehand and uses them to extract candidate responses in different directions from a single LLM agent. For example, we can use the following templates:
These templates intentionally cause shifts in direction and differences in depth to guarantee diversity of the candidate responses. The types and expressions of templates may be flexibly changed according to the topic, purpose of use, etc., so that the breadth of the discussion can be freely adjusted. 3.3 Evaluation of candidate responses: Achieving both naturalness and diversityTo decide on which response should be selected from the candidate responses generated as described above, two important criteria are connection to the discussion thus far and the existence of new perspectives. To meet these two criteria, we convert a response to a numerical vector by embedding*5 and evaluate it by assigning a score using the following two distance metrics:
For example, a candidate response that is highly related to the immediately previous response while being greatly different from the content of the past discussion would be judged a natural and novel response and receive a high evaluation. Conversely, a candidate response that is far removed from the immediately previous response or is nearly the same as past content would receive a low evaluation. 3.4 Automatic response selection based on evaluationAfter evaluating the candidate responses as described above, the candidate with the highest score is selected and adopted as the LLM agent’s next response. Such a selection process is completely automatic requiring no checking or adjustment by a user. Let us consider a discussion among LLM agents on the topic of elderly support in a regional area. The policy of providing the elderly with opportunities for going out was shared in responses, and the proposal that “regional exercise events should be increased” was offered in the immediately previous response. Under these conditions, the following three responses were generated as candidates:
The content of candidate B is near that of past responses and in line with the context of encouraging the elderly to go out, but it is judged to be lacking in novelty. Candidate C includes a completely different viewpoint (i.e., nutrition) and is therefore novel, but it is judged to deviate from the flow of the discussion. Candidate A, however, clearly connects with the immediately previous point of discussion on exercise while presenting a different perspective from going out. For these reasons, it is highly evaluated as a response achieving a good balance between novelty and naturalness, and it is finally adopted. A response having a new viewpoint and flowing naturally with the discussion is automatically selected, preventing simple paraphrasing or repetition and achieving a discussion that evolves in a meaningful way. Since responses are selected on the basis of fixed evaluation criteria, it is expected that the discussion flow will be consistent and be highly interpretable.
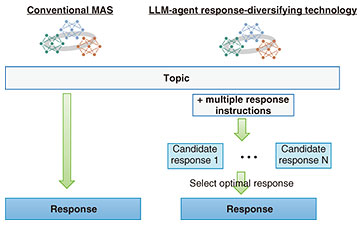
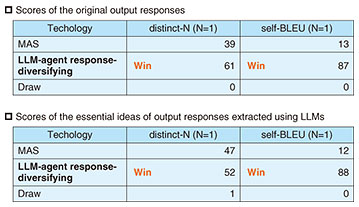
4. Experimental evaluation: Application to brainstorming on preventing the need for nursing care in a local governmentWe applied LLM-agent response-diversifying technology to a brainstorming session on preventing the need for nursing care as one regional issue facing local governments. We set up five LLM agents (e.g., an occupational therapist, welfare coordinator, and a doctor) as stakeholders within a local government and had them discuss and brainstorm about preventing the need for nursing care each from different positions. Within the discussion, we used LLM-agent response-diversifying technology to generate multiple responses and select the optimal one. To assess the effectiveness of our technology, we conducted the following quantitative evaluation. We first held ten discussions under the same topic and LLM-agent configuration for both the conventional MAS and LLM-agent response-diversifying technology, and generated responses for each agent. A response from each agent included not only an idea but also the reason for presenting it. Thus, in addition to the original output responses in each discussion, we also used only the ideas extracted from LLMs from output responses as evaluation targets. The differences between the conventional MAS and LLM-agent response-diversifying technology are shown in Fig. 3. To evaluate whether mutually similar opinions can be suppressed in both the original output responses and their essential ideas, we used distinct-N*6 [3], which measures the text diversity on the basis of the ratio of unique N-grams*7 in the generated sentences, and self-BLEU (Bilingual Evaluation Understudy)*8 [4], which measures similarity between texts on the basis of the BLEU*9 score. We made a total of 100 comparisons in the form of a competition between the conventional MAS and our technology and calculated the number of wins for each result in this competition on the basis of distinct-N and self-BLEU.
The evaluation results are shown in Table 1. LLM-agent response-diversifying technology performed better than the conventional MAS in all cases (i.e., for both the original output responses and extracted essential ideas, and on both distinct-1 and self-BLEU scores). These evaluation results indicate that our technology could make the vocabulary in a discussion more diverse than the conventional MAS.
To evaluate whether our technology could produce natural discussions in which point of discussion intersect, we used the results of a questionnaire given to the participants of a workshop on regional issues. While the details are described in the article titled “Field Trial and Future Outlook of AI Constellation” [5], the results indicate that our technology generated natural discussions in subjective evaluations. LLM-agent response-diversifying technology can thus be used in workshops and other forums studying regional issues. We expect it to be applied in even more diverse ways such as to local government measures and consensus building.
5. Future developments and issuesThis article introduced LLM-agent response-diversifying technology for generating diverse and natural responses in discussions among LLM agents. It was shown that the use of instruction templates and a mechanism for automatically evaluating candidate responses and selecting the optimal one could achieve better performance than the conventional MAS without human intervention. This technology is one of the technical elements that play core roles in discussions within AI Constellation in which LLM agents create a solution from diverse viewpoints. We plan to take on the application of specific use cases and promote research and development on technical issues such as a mechanism for appropriately recording and using past discussions and points of discussion. References
|
||||||||||||||||||||||||||||||