|
|
|
|
|
|
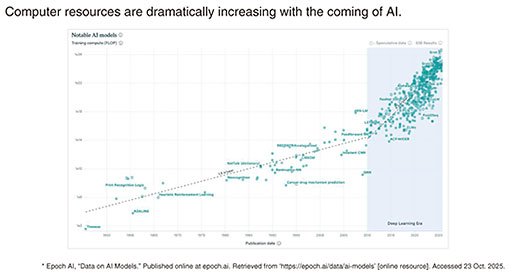
Feature Articles: Keynote Speeches at NTT R&D FORUM 2025―IOWN∴Quantum Leap Vol. 24, No. 3, pp. 29–40, Mar. 2026. https://doi.org/10.53829/ntr202603fa2  IOWN∴Quantum LeapAbstractThis article presents NTT’s research and development efforts to make quantum leaps. It is based on the keynote speech given by Shingo Kinoshita, NTT senior vice president, head of research and development planning, at the “NTT R&D FORUM 2025—IOWN∴Quantum Leap” held from November 19th to 26th, 2025. Keywords: photonics-electronics convergence (PEC) device, optical quantum computer, generative AI  1. NTT R&D Forum 2025 overviewThe theme of NTT R&D Forum 2025 is “IOWN∴Quantum Leap.” A quantum leap has two meanings. One is a leap forward in quantum mechanics and the other is dramatic progress in business. We aim to achieve a quantum leap in both technology and business. Let me explain why we need a quantum leap. In the current age of artificial intelligence (AI), computation amounts have been dramatically increasing. In Fig. 1, the horizontal axis represents calendar years, and the vertical axis represents computing resources. The area in blue highlights a sharp increase since the beginning of the AI era, meaning that a massive amount of resources is required. For example, for ChatGPT-4, the power consumption required for learning was said to have been about 40,000 MWh. This is equivalent to the power generated by 40 nuclear power plants. Therefore, the largest technological question we must answer globally is “Must computer resources continue to increase in this way toward the future evolution of AI?”
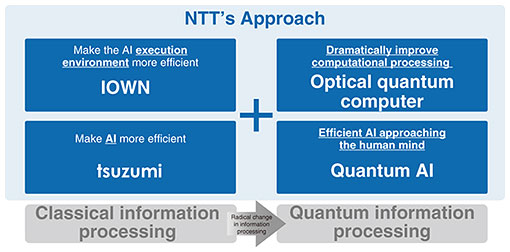
We at NTT are taking four approaches to address this question (Fig. 2). The two approaches on the left in Fig. 2 are within the scope of classical information processing. The IOWN (Innovative Optical and Wireless Network) approach aims to improve the efficiency of the AI execution environment. The other approach uses tsuzumi, a large language model (LLM) that is more lightweight and efficient than other LLMs. We plan to expand the scope of information processing from classical to quantum (Fig. 2, right) to address the above question. These approaches use optical quantum computers, which dramatically improve computational performance, and quantum AI, a highly efficient AI similar to that of the human brain. We address this question by combining these four approaches. With all of this in mind, I would like to share NTT laboratories’ research results on the topics of quantum, IOWN, and generative AI (Gen AI).
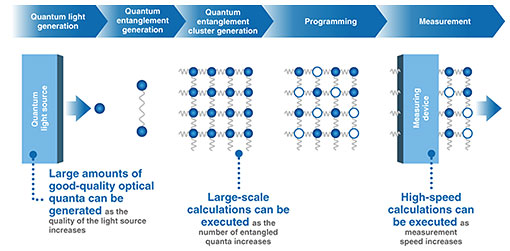
2. Quantum2.1 Quantum computingEven with the latest computer and AI technologies, critical problems remain, and interest in quantum computing is growing. Quantum computing research has advanced, ushering in a wave of industrialization. The quantum computing market is expected to grow to tens of billions of dollars by the 2030s, and expectations are higher than ever before. Quantum computing takes many forms—superconducting, neutral-atom, and optical. NTT is pursuing an optical approach as NTT is rooted in optical communication technology. By harnessing the nature of light, it achieves high speed, low power, and extraordinary scalability. It naturally integrates with communications, connecting seamlessly with future networks. We are leading quantum computing to its next stage—through the power of light. This is a new computational foundation for a sustainable society as it maximizes energy efficiency. Through collaboration between industry and academia, and the expansion of the optical quantum community, we aim to develop a large-scale, general-purpose optical quantum computer by 2030. Global-scale quantum computing will run on the IOWN computing platform in the future. 2.2 Basic operation of an optical quantum computerI would like to give a brief introduction to the basic operation of an optical quantum computer (Fig. 3). Quantum light is first generated by a quantum light source. A quantum entanglement, which is key for quantum computer, is then created to maintain the relationship between two quanta. This entanglement is then expanded into a mesh-like structure, generating a cluster. The next step is programming, which is done by operating on each quantum. The final step is calculation, which is done by measuring the quantum states.
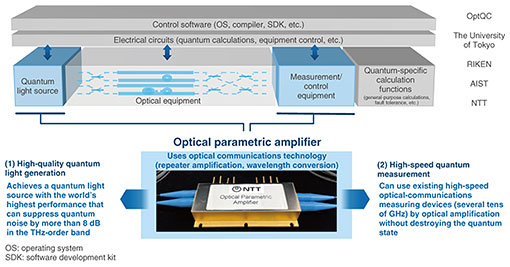
There are three solutions we are investigating to improve the performance of optical quantum computers during these steps. First, the higher the quality of the quantum light source, the larger the amount of high-quality optical quanta (quantum light) can be generated. Second, the more quantum entanglements, the larger the scale of calculations can be executed. Finally, the faster the measurement speed, the faster the calculations can be executed. The actual hardware and software configuration of the optical quantum computer is shown in Fig. 4. Quantum light is first generated from the quantum light source, then quantum entanglements and clusters are generated using optical equipment. Finally, quantum programming and measurements are done using measurement and control equipment. NTT is researching the areas of quantum light sources and measurement/control equipment, where optical parametric amplifiers are used.
An optical parametric amplifier has been used in optical communications for repeater amplification and wavelength conversions. We have attempted to apply this device to quantum computing and achieved high-quality quantum light generation. We also confirmed that this device enables high-speed quantum measurement. Optical communications and optical quantum computing have a strong affinity. High-quality light-source and wavelength-conversion technologies for the transmitter in optical communications can be applied to quantum light sources. Wavelength-division-multiplexing technology as well as technologies for low-loss optical fiber and multi-core fiber can be applied to optical equipment for optical quantum computers. Optical high-speed detection technology for the receiver and optical amplification technology can be applied to quantum measurement. Therefore, the technologies developed for optical communications can be used in a variety of ways for optical quantum computers. 2.3 Features of optical quantum computersWhen people think of quantum computers, they might imagine a superconducting system, which requires huge refrigeration/vacuum equipment. How to downsize such equipment connected to a small quantum chip is extremally difficult. In contrast, an optical quantum computer can be configured with optical equipment, such as light sources and mirrors, and can operate at room temperature and normal pressure, making huge refrigeration/vacuum equipment unnecessary and downsizing the computer much easier. To increase the performance of a quantum computer, how to increase the level of parallel processing and the overall amount of computation is an issue. Approaches to address this issue include spatial multiplexing and time multiplexing. Superconducting systems rely on spatial multiplexing, and equipment parallelization is necessary to increase qubits in a quantum entanglement state. However, as I mentioned earlier, it is difficult to downsize the refrigeration/vacuum equipment; therefore, as one scales up, one ends up needing more installation space. Even if chips can be integrated, the size of refrigeration/vacuum equipment hits a bottleneck, limiting scalability. Optical quantum computers, on the other hand, benefit from time multiplexing. By connecting entangled states created in consecutive time slots along the time axis, the number of qubits can be increased in an almost infinite manner. By reducing the interval between these time slots, that is, by increasing the operating frequency, the degree of time multiplexing can be increased. As the communication speed increases, the number of entangled qubits grows, giving optical quantum computers a clear advantage in scalability. Time multiplexing can also be increased by improving the quality of the light source or by speeding up the measurement device, allowing operating speed to increase from the current 10 GHz to about 100 GHz. In addition, optical quantum computers can leverage the ability of optical communications to multiplex wavelengths. Multiple wavelengths can be sent through a single fiber simultaneously. We believe that by combining wavelength multiplexing and time multiplexing, operating speed can increase from 100 GHz up to 10 THz. To summarize the features of optical quantum computers:
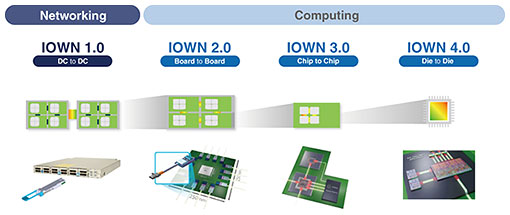
With these features, optical quantum computers offer tremendous scalability compared with other systems for quantum computing and are receiving significant attention worldwide. Everything I have explained thus far has been about a single quantum computer. By placing multiple optical quantum computers worldwide and connecting them through IOWN and all-photonic quantum repeater technology, we believe it will be possible to create a global network of distributed entanglement. Toward this goal, NTT entered into a business partnership with OptQC, a venture company founded by researchers from the Furusawa Laboratory at the University of Tokyo. Together, we aim to build the world’s leading optical quantum computers, with plans to achieve 10,000 qubits in 2027 and 1 million qubits in 2030. 3. IOWN3.1 IOWN roadmapLet me first explain the IOWN roadmap (Fig. 5). In IOWN 1.0, which is in the domain of networking, the goal is to make the connection between datacenters fully optical. From IOWN 2.0 onward, we enter the domain of computing. In 2.0, the aim is to make the connections between sever boards fully optical. In 3.0, the connections between chips on a board become optical. In 4.0, the connections between dies inside a chip become optical.
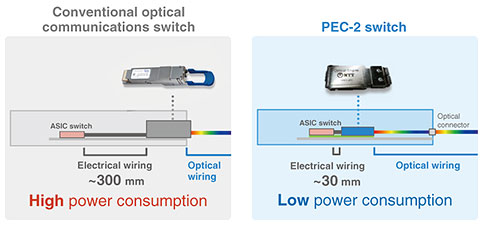
3.2 IOWN optical computingNTT supports the evolving “communications of the future” with “low power consumption through light,” with its IOWN Photonic Disaggregated Computing from both the hardware and software perspectives. In terms of hardware, electrical signals will be replaced with optical signals, reducing power consumption and achieving high-speed communication with low latency. In terms of software, large-scale computers that require advanced processing have traditionally had restrictions on the combination of parts, necessitating the installation of additional cabinets, which consumed power even for parts that were not being used. However, by removing these restrictions and using resource allocation technology that allows for only the necessary functions to be used in the amounts required, we have achieved more advanced processing and reduced power consumption. At Expo 2025 Osaka, Kansai, Japan, these technologies were used for AI-based image processing, enabling resources to be operated only as needed, thus reducing power consumption of up to 1/8 of previous levels. By combining these technologies with the ultra-high-speed All-Photonics Network, it will be possible to use computers in remote locations as if they were a single high-performance computer. This will enable efficient use of electricity near renewable energy sources and power-generation facilities. Optical fiber had been traditionally used for long-distance transmission, such as over 100 km, and electrical wiring for extremely short-distance transmission, such as 10 cm or 1 m, inside servers. However, the required communication speed between graphics processing units (GPUs) for AI computing has increased, and 14 or 15 Tbit/s are now required even at distances of only 10 cm or 1 m. Electrical wiring cannot support such high-speed transmission. Therefore, the technical challenge we now face is how to transmit signals using optical wiring efficiently over distances of 10 cm to 1 m. 3.3 Reduced power consumption in PEC-2 switchWe are working to improve transmission efficiency between boards and prototyped the second generation of a photonics-electronics convergence (PEC) device called PEC-2 (Fig. 6, right). In a conventional optical communications switch (Fig. 6, left), a pluggable transceiver is installed at the front of the switch. After an optical signal enters the transceiver, the signal is transmitted through electrical wiring. The distance between the transceiver and application-specific integrated circuit (ASIC) switch is a short distance of about 300 mm; however, 15-Tbit/s transmission through electrical wiring generates a large amount of heat, increasing power consumption.
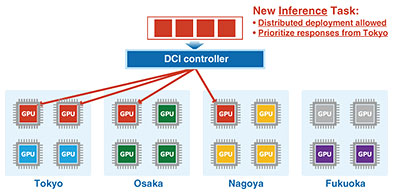
In contrast, with the PEC-2 switch, an optical signal can reach near the ASIC switch. We thus can reduce the distance of electrical wiring to 30 mm, which reduces power consumption. We announced that we will commercialize the PEC-2 switch, the communication capacity of which will be twice that of the protype version, by the end of fiscal year 2026. Toward commercialization, the ASIC switch will be provided by Broadcom; the optical engine, i.e., the PEC-2 device, will be provided by NTT Innovative Devices; and the switch module consisting of these devices will also be manufactured by NTT Innovative Devices. Assembling them into a switch box will be handled by Accton. By combining the PEC-2 switch with GPU servers, we will make optical computing a reality. We are also developing software to support the future operation of GPU clusters. A GPU cluster can be configured with composable servers from Accton, Erut, and Fsas as well as general-purpose GPU servers from Dell and Supermicro. By connecting these GPU servers with the PEC-2 switch, and by using the Data-Centric Infrastructure (DCI) controller, we can optimize and efficiently manage a large number of GPU resources. Let us discuss the example of datacenters distributed across Tokyo, Nagoya, Osaka, and Fukuoka. Not only the unified monitoring of each datacenter’s GPU availability and faults, traffic conditions, and power consumption but also dynamic control will be carried out (Fig. 7). Consider each datacenter has four GPUs. The blue, purple, and yellow GPUs represent those that are already running tasks, and the gray ones are idle. Now suppose four new AI inference tasks arrive. These four tasks do not need to be allocated in the same location, but there is a requirement to prioritize the response time from Tokyo. In this case, the DCI controller will allocate two tasks in Tokyo, one in Osaka, and one in Nagoya (red GPUs in Fig. 7). This allocation is done automatically while monitoring GPU conditions in each datacenter.
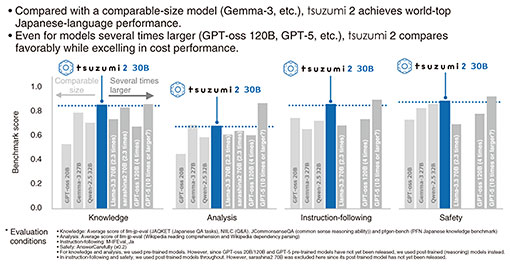
Let us next consider four AI training tasks arrive. For AI training tasks, distributed allocation reduces performance, so the requirement is to allocate them together as much as possible. Therefore, the DCI controller might transfer AI inference tasks running in Fukuoka to Tokyo to free up four GPUs in Fukuoka then assign new AI training tasks there. This kind of optimization is handled by the DCI controller automatically. 4. Gen AI4.1 Release of tsuzumi 2We announced the first version of tsuzumi in March 2024. At that time, the model size was 7 billion (B) parameters. We released the second version in October 2025, the model size of which is 30B. Why 30B? The reason is that this is roughly the maximum model size that can run on a single latest-generation GPU. So why is running on one GPU important? Because it enables on-premise or private-cloud deployment of an LLM at low cost and with high security. There are four features of tsuzumi 2. The first is further improvement in Japanese-language performance. In Fig. 8, the horizontal axis represents the evaluation criteria of LLMs used in Japanese-language benchmark tests: knowledge, analysis, instruction-following, and safety. The vertical axis shows the scores: higher is better. The blue bars are the results for tsuzumi 2. The grey bars show other companies’ models of comparable size, which are, from left, OpenAI’s GPT-oss 20B, Google’s Gemma-3 27B, and Alibaba’s Qwen-2.5 32B. These three models are said to be among the best in the world, yet tsuzumi 2 outperforms them in Japanese-language performance. We also compared tsuzumi 2 with larger-parameter models. These include Meta’s Llama-3.3 70B, SoftBank’s sarashina2 70B, GPT-oss 120B, and GPT-5. GPT-oss is about four times larger than tsuzumi 2, and GPT-5 is estimated to be more than ten times larger, although the exact size is unknown. Even in comparison with these larger models, tsuzumi 2 performs quite well, demonstrating that it is a highly efficient Japanese-language LLM.
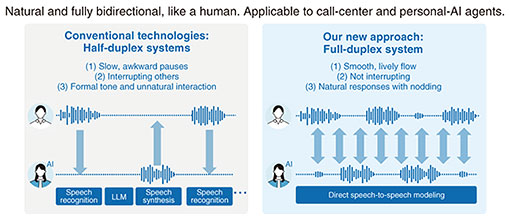
The second feature is improved efficiency in developing specialized models. Rather than aiming it to be a general-purpose model, tsuzumi 2 is designed as a specialized model, so it has been trained heavily on data from fields such as finance, healthcare, and public administration. We evaluated the performance of tsuzumi 2 using the 2nd-grade Certified Skilled Professional of Financial Planning (CSPFP) exam as a financial benchmark. We evaluated how the score changes when the model is given 200, 500, and 1900 practice questions. For Google’s Gemma, the score started at 39 with no practice questions. Only after 1900 practice questions did it reach 64, which is the 2nd-grade CSPFP exam passing line. In contrast, tsuzumi 2 started at 54. It did not reach 60 immediately, but after just 200 practice questions, it reached 70, surpassing the exam passing line. This means tsuzumi 2 reached the required performance level with roughly one-tenth the training data, demonstrating very high efficiency. The third feature is low cost and high security. For example, running DeepSeek 700B requires about 16 units of the NVIDIA H100 GPU, and the hardware cost alone is said to be roughly 100 million yen. In contrast, tsuzumi 2 can run on a single A100 GPU, which is three generations older, and the hardware cost is about 5 million yen. This results in a cost advantage of 10 to 20 times. The fourth feature is that it is a domestically developed AI. From the standpoint of maintaining sovereign AI, which has been gaining attention worldwide, tsuzumi 2 has advantages from the following perspectives: (1) Sovereignty of language and culture (correctly comprehend Japanese and preserve language and culture within the language model) (2) Sovereignty of training data (ensure the model is not trained on data that violate copyright and have full control over what data are selected) (3) Sovereignty of development process (determine the development schedule and methods) (4) Sovereignty of licensing (maintain control over licensing) (5) Sovereignty of technology (enable R&D of AI technology slated to become the key technology of the future without relying on other countries) 4.2 Application of Gen AIConventional conversational AI systems were half-duplex, where the AI speaks and finishes speaking, the user speaks and finishes speaking, then the AI speaks again. This created pauses and poor timing, and if both sides spoke at once, the AI would interrupt the user. The tone of the AI also tended to sound stiff. To address this issue, we developed a full-duplex system (Fig. 9), which is a speech-to-speech system. Instead of taking spoken audio, turning it into text with speech recognition, sending that text to a language model, receiving a text answer from the model, then synthesizing it into speech, we directly input the spoken audio as training data then train the system on the conversational context. The conversation overlaps naturally, the tempo is smoother, and even when both sides start speaking at once, the AI does not interrupt the user. The AI sounds much more natural and human like.
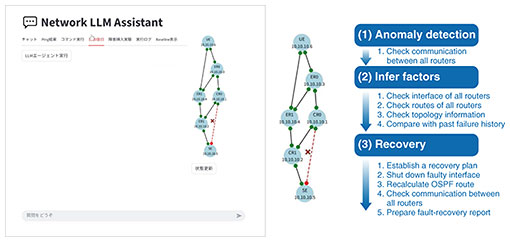
We developed this system in a little under six months. At the early stage of the development, the AI sounded awkward. Because it is a speech-to-speech system, it is quite difficult to control, and there are many examples of failure such as repeating the same question twice and accepting the credit card number the user told even when missing 1 out of 16 digits. Because the system learns conversational patterns, it still cannot handle accuracy requirements well. This is one of the technical challenges. Another challenge is that call centers often receive calls from very angry customers. Professional operators would lower their tone and adjust their response style. How should AI react in those situations? There are still many research challenges that remain. Another application example of Gen AI is network operations and monitoring, which is a core area for NTT. We are now applying AI agents to this domain. Figure 10 shows a network configuration, in which the blue circles represent network devices and lines represent communication links. Say this red link has failed. The AI agent inspects the network, diagnoses the issue, restores the connection, and finally prepares a recovery report. All steps from anomaly detection, inferring factors, and recovery are automated by AI.
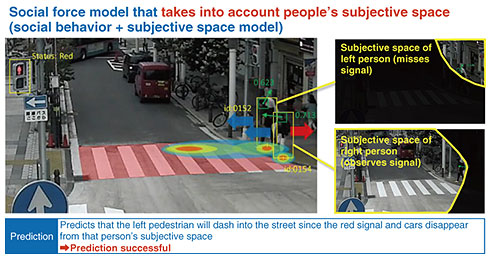
4.3 Non-language large-scale modelsWe are developing what we call a large action model. A language model predicts the probability of the next word appearing in text. An action model works in the same manner: after someone performs action A, the probability that they will perform action B is predicted. We built a probability model of actions and applied it to marketing and promotion. For example, based on a person’s past behavior, such as viewing news then seeing an advertisement and receiving reward points, we calculate probabilities for what will happen next if we (i) do not take any promotional measures (ii) send direct mail, or (iii) make a phone call. For instance, when we do not take any promotional measures, the probability of changing a fee plan is 7%, probability of purchasing a smartphone is 1%, and probability of adding an optional video service is 4%. If we send direct mail, the probabilities of changing a fee plan is 8%, purchasing a smartphone is 1%, and adding an optional video service is 4%. If we make a phone call, the probabilities of changing a fee plan is 20%, purchasing a smartphone is 2%, and adding an optional video service is 8%. Since it shows that a phone call is the most effective, we use phone calls for promotion. In fact, when we used phone calls for NTT DOCOMO telemarketing, the order closing rate (number of people accepting offer/number of people called) doubled. A world model refers to AI that understands the world not only through language but also through vision and other sensory inputs. It is sometimes called physical AI and is rapidly gaining attention. We are developing a mobility AI platform together with Toyota. In autonomous driving, it is now said that we must move beyond a self-contained approach that relies only on the car toward a triad of cooperation among people, cars, and infrastructure. At NTT, our research focuses on how to efficiently predict human behavior. Suppose two people are crossing the street at a pedestrian crossing. One person notices a car is approaching and stops while the other is distracted and steps forward and is almost hit by the car. The question is whether AI can predict these two different behaviors in advance. A naïve model makes predictions on the basis of the assumption that physical motion simply continues and cannot predict these two behaviors in this situation. A more advanced social behavior model uses a balance between attractive forces from a destination and repulsive forces from obstacles, such as cars or red lights, and predicts when someone will stop. This model’s prediction also fails. NTT uses a social force model that combines social behavior with a subjective space model (Fig. 11). The person on the right is facing forward and can see the traffic signal while the person on the left is facing in a direction where the traffic signal is not visible and only sees what’s above it. By modeling this difference in what each person perceives in their subjective space, the model predicts their behaviors correctly. A social force model does not treat people as simple physical objects but predicts their behaviors on the basis of social and cognitive factors.
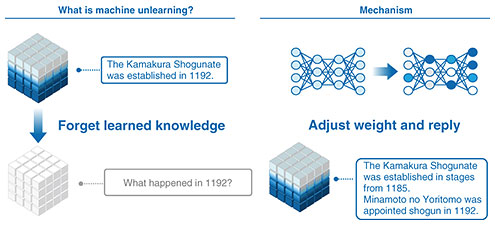
4.4 Research toward artificial general intelligence and artificial superintelligenceThe first topic is Mind Captioning, which was developed by NTT. This technology measures brain activity of a person watching a video or recalling something by using functional magnetic resonance imaging then turns that brain activity into text. When we examined video-identification performance to evaluate Mind Captioning on the basis of similarity scores between the generated text and human-written reference descriptions, we obtained an interesting finding. High-accuracy text generation was possible even when activity in language-related brain regions was excluded from the analysis. This suggests that this technology captures non-verbal semantic information, rather than verbal information, and verbalizes it. If that is true, it might enable us to verbalize what is being seen by measuring the brainwaves of people with damaged language areas, infants who have not yet acquired language, or even animals. We are also conducting research on machine unlearning (Fig. 12). This research focuses on how to make a model forget data it has already learned. It will be useful, for example, when a model is found to have learned data that violate copyrights and someone asks to remove those data. To truly remove them, the model would have to discard that portion of the training set and be retrained from scratch, which is extremely costly. In contrast, machine unlearning enables us to efficiently delete only a specific piece of knowledge from a complete model. If this becomes practical, issues such as copyright problems will become much easier to handle.
The third topic is the psychological mechanism of LLMs. Until recently, LLMs were said to hallucinate often, tell lies, and be uncontrollable. However, recent research has shown that within an LLM there are sets of neurons that strongly react to particular meanings such as a lie, kindness, or guessing. This finding enables us to create an LLM lie detector. By observing certain neurons in an LLM, we can understand whether the model is lying. It may thus become possible to slightly adjust those neurons so that the model stops lying. This can also be applied to hallucinations and many other issues, and research on this topic is now rapidly progressing worldwide. The final topic is quantum AI. Today’s AI runs on enormous amounts of energy; thus, quantum AI is now a focus. By harnessing light’s superposition and interference, research is pursuing deeper learning with less energy. This evolution is not one-way. Quantum advances AI, and AI refines quantum—a time when intelligence renovates and accelerates. Quantum AI is beginning to grasp the hidden patterns within the world. A quantum computer is much closer to an analog computer than today’s classical computer. Quantum computers are extremely sensitive to noise, and we are investigating whether we can take advantage of that noise. After all, the human brain and language data are also full of noise. This idea of how far we can exploit noise in a positive way is also a target of our research. Toward the future evolution of AI, we at NTT pursue R&D on IOWN, tsuzumi, optical quantum computers, and quantum AI within the scope of both classical information processing and quantum information processing. |