|
|||||||||
|
|
|||||||||
       |
Front-line Researchers Vol. 24, No. 6, pp. 1–7, June 2026. https://doi.org/10.53829/ntr202606fr1  An Experimental Psychologist’s Challenge to Uncover the Mechanisms of Visual Information Processing and Transmitting the Sense of Materials to Remote LocationsAbstractObjects that look so soft they almost invite touch as they move. Images that seem ready to spring into motion at any moment. What perceptual mechanisms enable the human visual system to evoke such vivid impressions? Takahiro Kawabe, a senior distinguished researcher at NTT Communication Science Laboratories, approaches this question from a unique vantage point. With a background in psychology, he leverages computational methodologies to uncover the underlying principles of visual information processing in the brain. He is also driving efforts toward the real-world deployment of technologies capable of transmitting the visual sense of materiality across distance. In this interview, we explore his latest research achievements and the future directions of his work. Keywords: visual material perception, perception of the direction of timelines, perception of the direction of liquid flow
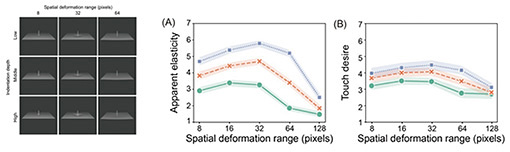
Softness and touch desire are perceived visually—Would you tell us about your recent research? I’m currently conducting research on vision. Although vision research encompasses many different approaches, my focus is specifically on human vision rather than machine or computer vision. In my previous interview for this journal, I spoke about my research on visual material perception. My work explores human vision through psychological approaches, with the goal of identifying the key parameters that define how we perceive materials. By capturing these parameters, I aim to enable the transmission of material impressions across distances. Ultimately, I am working toward developing technologies on the basis of this understanding and bringing them into real-world use. Let me first talk about research on visually recognizing and identifying softness and “touch desire.” In an experiment, I first prepared a single plane in a virtual space generated using computer graphics (CG). I then recorded (as videos) the action of pushing a needle-shaped rod into the plane and releasing it. Next, I evaluated how a human would perceive the “indentation depth” (i.e., how deeply the rod indented the plane) and the “spatial deformation range” (how much the plane is deformed laterally by the indenting rod) (Fig. 1).
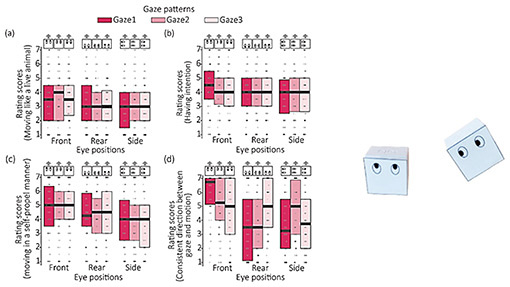
At a spatial deformation range of 8 pixels, the deformation of the plane is only visible around the rod; however, at 32 pixels, the wider area of the plane appears to be indented and deformed. At 64 pixels, at first glance, the plane doesn’t appear to be deformed, but on closer look, the entire plane has deformed as if it were bending downwards. The graphs on the right of Fig. 1 show the results of asking participants about their perception of “apparent elasticity” (softness) (graph (A)) and touch desire (graph (B)) after they watched the video. The horizontal axis of both graphs represents the spatial deformation range. The indentation depth is represented by each plot in the graphs in increasing order of green, orange, and blue. The overall shapes of the plots in graphs (A) and (B) are similar, and that similarity indicates a clear correlation between what humans perceive as soft and what they desire to touch. In both graphs, the blue plots, representing greater indentation depth, indicate that the images were perceived as the softest and most desirable to touch, while the green plots, representing smaller indentation depths, indicate that the planes were perceived as less soft and less desirable to touch. Regardless of the indentation depth, the planes were perceived as the softest and most desirable to touch when the spatial deformation range was moderate. According to previous research, the indentation depth affects perceived softness and touch desire; however, my study is the first to demonstrate that spatial deformation range also plays a role in these types of perception. Conventionally, when the softness of an object is conveyed remotely, it could only be expressed by the indentation depth in a manner that limits the means of conveying this touch desire. However, my study demonstrated that the spatial deformation range is also a parameter that conveys softness and touch desire; in other words, using the spatial deformation range to manipulate the surface deformation in images makes it possible to increase the number of ways we can express them. I had the opportunity to explain this research on visual material perception to Shiseido, a cosmetics company focusing on “beauty tech,” and in September 2025, we began joint research to explore the possibility of conveying the texture and feel of cosmetics as visual information [1]. We are considering augmented reality, for example, as a possible means of conveying textures that are difficult to convey through product images alone. Shiseido is currently testing NTT’s technology, and I believe we will be able to share the results of this collaborative research in the future. —You are researching the lifelikeness and intention of objects from a visual perspective, correct? Correct. I am conducting research on the perception of “animacy” and intention through sight. Apart from perceiving feel, such as softness and weight, sometimes people perceive inanimate objects, such as robots or CG characters, as if they were alive or as if they were moving with intention. We are exploring how animacy and intention manifest themselves in such objects. The practical goal of this research is to create robots and CG characters that are lifelike with readable intention. Specifically, we are researching where to place the eyes on a cube-shaped robot that can move freely on a two-dimensional plane and in what direction to orientate the robot’s gaze in such a manner to make the robot look more lifelike. We concluded that when the eyes are positioned at the front in the direction of movement, it gives the impression of the robot being lifelike or moving autonomously. Interestingly, while the position of the eyes is important, the direction of the robot’s gaze does not have much influence on lifelikeness (Fig. 2).
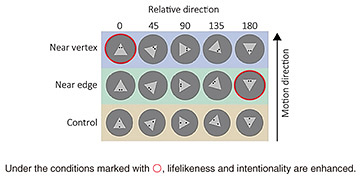
Compared with other primates, humans have a certain proportion of white in their eyes, clearly exposed sclera (white background), which gives humans a strong ability to read the direction of others’ gazes and their intention. Other mammals, such as dogs and cats, have a smaller proportion of white in their eyes. I hypothesize that in regard to the evolution of organisms, the position of the eyes, rather than which direction they are looking, may have been a more important factor in lifelikeness. I believe that our research findings could give us some clues when designing the eye placement for future robots. In another experiment, I showed participants a video showing a triangle moving freely and asked to evaluate the perceived lifelikeness of the triangle. The results of the experiment indicate that when the vertex of the triangle was aligned with the direction of the triangle’s movement (that is, when the triangle moved freely with the vertices at the front), the triangle was perceived as lifelike. On the contrary, if the vertex of the triangle is misaligned with the direction of movement, it appears as if the triangle is being carried away by water or wind. In other words, the assessment of the misaligned triangle was that rather than a living creature moving, it looked like an object being carried along by a current. We then experimented to see what happens when we placed eyes on the triangle and found that even if the direction of the vertex and the direction of movement match, the figure looks more lifelike when the eyes are at the front in the direction of movement (Fig. 3).
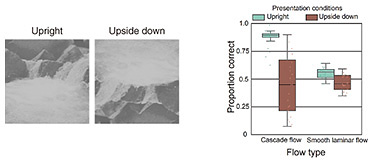
The results of this experiment indicate that while humans process information by combining eye position and object shape, eye position alone is an important factor considered by humans processing direction of movement. We can therefore conclude that eye position is an important factor to be considered when creating industrial robot designs. —Would you tell us about your basic research aimed at explaining the mechanism of vision by using the perception of the direction of timelines as an example? We humans can see things because light enters our eyes and tend to think that all the information processing takes place in the eye; however, it’s not that simple. Information entering the eye first hits the retina, where it is converted into neural-activity signals, which are transmitted to the brain. Step-by-step processing of those signals then takes place in the brain in a way that we perceive as “seeing.” The brain is hierarchically divided into areas responsible for processing time, space, movement and motion, and direction. By meticulously investigating each of these processing mechanisms, we can reveal how humans perceive things from light patterns. In other words, these fundamental investigations will unravel the mechanisms of vision. I’ll introduce research that investigates the perceptual mechanisms of the direction of timelines and that of liquid flow. From an academic perspective, this research is useful in understanding how the brain works when humans perceive objects, and I believe that understanding these brain mechanisms will also be useful in creating new methods for presenting information in the future. Using a video as an example, I’ll introduce the mechanism by which we perceive the direction of a timeline. Normally, we immediately notice when a video is being played backwards. Although the reason that we notice this state is not clearly understood, we have discovered a phenomenon that may provide a clue, namely, it becomes more difficult to notice that the video being played backwards when the videos are turned upside down and played backwards. For example, we created both an upright and upside-down version of a video showing a flowing river (liquid), and both videos were presented to viewers to watch for about four seconds. Two versions of the videos were then presented: one played normally and one played backwards. The viewers were then asked which version was the video played backwards. According to the answers, although all viewers could easily detect the rewound video in the upright version, the detection rate for the rewound video decreased when the video was upside down (Fig. 4).
This phenomenon is very strange. If humans were only extracting temporal information from videos and visual information, inverting videos shouldn’t have any effect. However, we showed that turning the video upside down makes a big difference to the detection rate. This phenomenon can probably be explained by the fact that turning the video upside down makes it difficult to understand the relationships between objects, that is, the “spatial structure.” When an upside-down image is viewed, while individual objects may be recognizable, their relationships to one another become difficult to understand. An example of this phenomenon is facial patterns; that is, when a face is upside down, it suddenly becomes difficult to recognize whose face it is. A famous example is the Thatcher illusion*1. When viewing an image in which the entire face is upside down but the eyes and mouth remain in the correct orientation, we view the image without feeling any unease. This phenomenon occurs because turning the entire face upside down makes it difficult to comprehend the individual elements in the image, so we view the whole image without any sense of unease. I believe that the results of this experiment are due to a similar phenomenon to the Thatcher illusion. When a video is turned upside down, the spatial structure becomes unclear, so it becomes difficult to determine which direction the water is flowing, for example, in footage of a flowing river. It therefore becomes difficult to determine whether the timeline of the footage is reversed or normal, making it difficult to detect video played backwards. In the video experiment I just described, when the video is upright, playing it backwards makes the water appear to flow from bottom to top. When the video is turned upside down, however, playing it backwards makes the water appear to flow from top to bottom. As shown by the brown bar graph on the left of Fig. 4, the detection rate (proportion correct) is low, indicating many people found the backward video to be more natural. From this finding, we can conclude that in scenes with various movements, the spatial structure of objects in the scene influences the perception of the direction of a timeline.
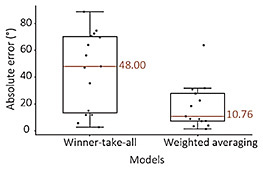
Simulating the function of brain cells involved in vision by calculations—Can you tell us about your basic research to explain the visual mechanism by using the perception of the direction of liquid flow as an example? When a river is flowing, we naturally understand its direction without consciously thinking about it. With that fact in mind, I investigated why we have this natural ability. Normally, solid objects don’t change much in shape or color, even when they move slightly. In contrast, liquids are fascinating substances. When they move, they create waves, which don’t just flow in the same shape; they disappear and reappear as they move in complex ways. Consequently, the patterns of light reflected by those waves also change. Regardless of these changes, we can easily discern the direction in which a liquid is flowing. Understanding why we have this ability is crucial in regard to fundamental research on vision. My research focuses on the function of cells in the brain that detect directions of movement, and I’ve used convolutional processing to simulate this function computationally. I showed videos of various flowing liquids to the simulated brain and asked it, “Which direction is this liquid flowing?” I then investigated what kind of calculations would produce results close to human responses; that is, what kind of calculation process closely resembles the mechanism of human vision. Many different types of cells in the brain recognize directions of movement. For example, some cells respond to upward movement in the visual field, some respond to downward movement, some respond to leftward movement, and some even respond to diagonal movement; in other words, each type responds to a specific direction. Considering this fact, this study investigated what kind of cellular information we use to perceive liquid flow. A common hypothesis in previous research is that if we look only at the output of the cell among many cells that reacts most strongly, we can determine the direction of movement. This approach is called “winner-takes-all”; namely, the “opinion” (output) of the cell that reacts most strongly dominates the decision. As shown with the left graph of Fig. 5, compared with the direction reported by experimental participants, the direction obtained using the winner-takes-all approach produced a large error of 48 degrees; therefore, we adopted a weighted averaging approach. This approach accounts for the responses of all cells, assigns weights on the basis of the strength of each response, and calculates the overall (weighted) average. When we used this approach, the error relative to the direction reported by the participants was reduced to approximately 10 degrees, which shows the results (directions) obtained with the weighted-averaging approach are closer to those obtained by human judgment.
—Would you tell us about your future plans? The NTT Science and Core Technology Laboratory Group, where I work, has set the goal of making world-first discoveries and developing world-class technologies. To reach that goal, I’m conducting research in the field of visual-information-processing mechanisms with the aim of making world-first discoveries of high scientific value. I’ve recently become interested in the shape of things. By “shapes,” I mean not only industrial designs created with a specific purpose, such as being user-friendly, but also things that exist in nature, and I believe that their shapes hold some kind of meaning. I want to investigate how people perceive the impressions they get when they see a shape. In other words, I want to determine the human perceptual characteristics that connect shapes with the various impressions that people get from them. For example, what kind of shape is considered “delicious”? What is considered a “lively shape”? I’m interested in the mechanisms by which we recognize shapes described with seemingly unrelated modifiers. Previous research has suggested a relationship between taste and shape, such as “sweet shapes” being slightly rounded and “salty shapes” being jagged. However, the detailed mechanisms of vision are still not fully understood, so I want to clarify those mechanisms. For example, I plan to investigate what constitutes an “appetizing shape,” how humans process such shapes with their eyes and brain, and the mechanisms through which such impressions are created. I believe that in the future, this knowledge could be applied to food advertising design and robot design. I also aim to implement our research findings in society. We are considering joint research with Shiseido, as mentioned earlier, to discover visual characteristics that enable the transmission of texture information to remote locations and to use those characteristics in society. Without a solid foundation, implementation of scientific knowledge only solves immediate problems and doesn’t allow for further development; that is, it tends to be merely a temporary solution. I learned the hard way when I developed “Hengento”*2 that a deep understanding of the mechanism of human vision processing allows various problems to be generalized. While firmly establishing a foundation in basic research, and given that I’m fortunate to be working at NTT, I also want to consider ways to use the results of my research activities for the benefit of society.
—What is your message to the next generation? Even amidst the hustle and bustle of daily life, I hope you cherish the time you take to reflect on yourself. It’s important to consider what you want to do—and what you should do—carefully, organize your thoughts in your own words, and develop a vision for the future. Putting it more simply, I believe it’s important to ask yourself repeatedly what kind of work you want to do in the future, and what you are currently working on to achieve that future goal in a manner that enables you to articulate that goal in your own words. It’s also important to have a clear picture in your mind of what your work will be like in the future and how it will be useful and to be able to explain that picture to anyone at any time. You may also find yourself taking on unexpected tasks through your interactions with the many people you will meet. Currently, I hold the positions of senior distinguished researcher and group leader. Originally, I aspired to make a living as a researcher, but I was also appointed as a manager, and now I am expected to lead a team toward the company’s goals. I view this experience as a good opportunity for my own growth and am working on it positively, but sometimes I find myself reflecting on what I originally wanted to do and what I should be doing and re-examining myself. It’s all very well when what you want to do aligns with the activities of the organization you belong to, but that’s not always the case. Sometimes slight discrepancies appear between your original vision and policies and what’s happening within the organization. However, I believe it’s important to understand the relationship between these discrepancies—instead of simply dismissing discrepancies as unavoidable—and firmly comprehend the relationship. I also believe that this accumulation of experience will bring a sense of satisfaction to your choices and serve as a supporting foundation when you look back on your life in the future. Reference
■Interviewee profileTakahiro Kawabe received a Doctor of Psychology from Kyushu University, Fukuoka, in 2005. In 2011, he joined NTT Communication Science Laboratories, where he studies human material recognition and cross-modal perception. He received the Young Scientists’ Award in the FY2018 Commendation for Science and Technology by the Minister of Education, Culture, Sports, Science and Technology. |
||||||||